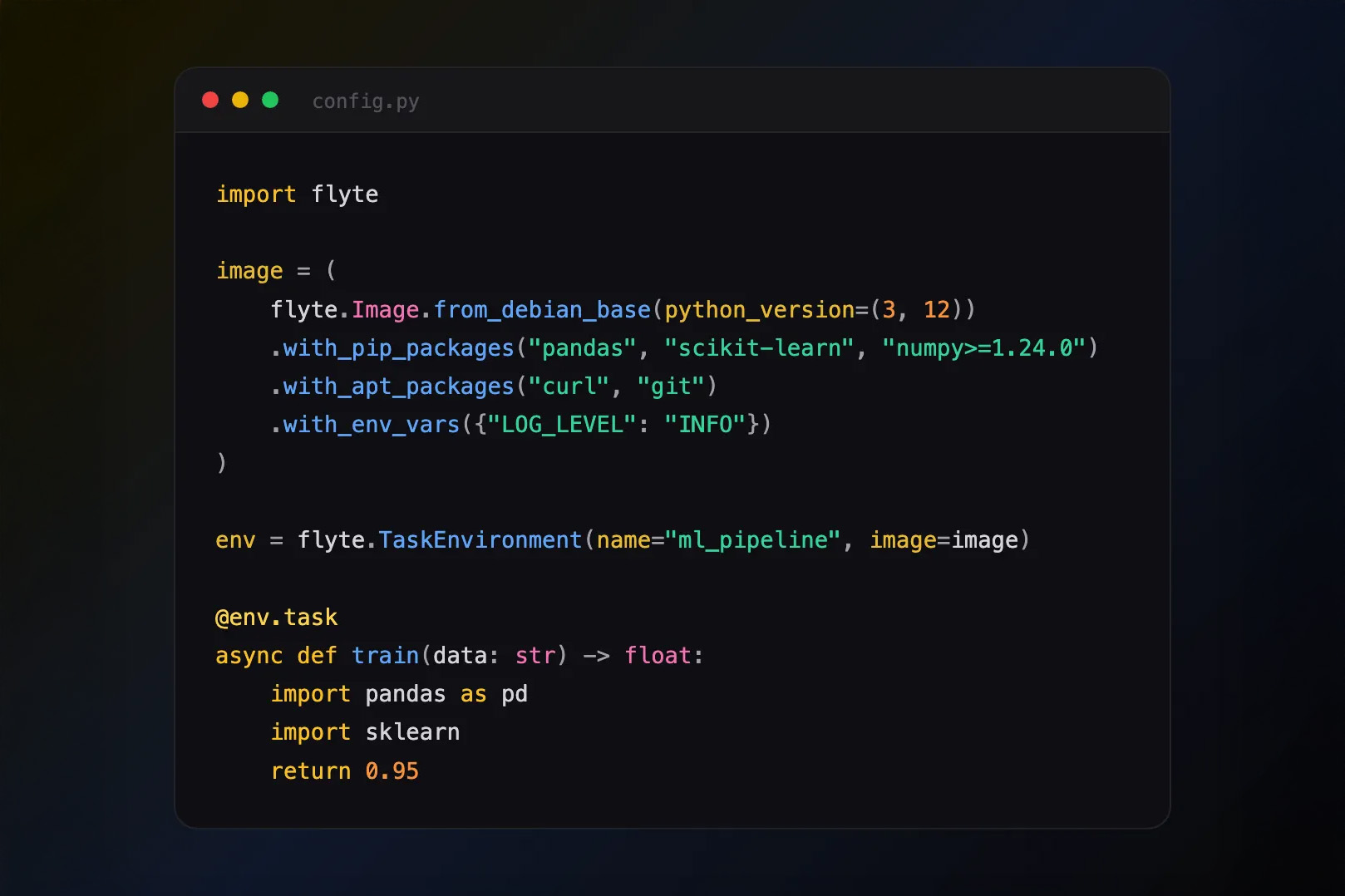
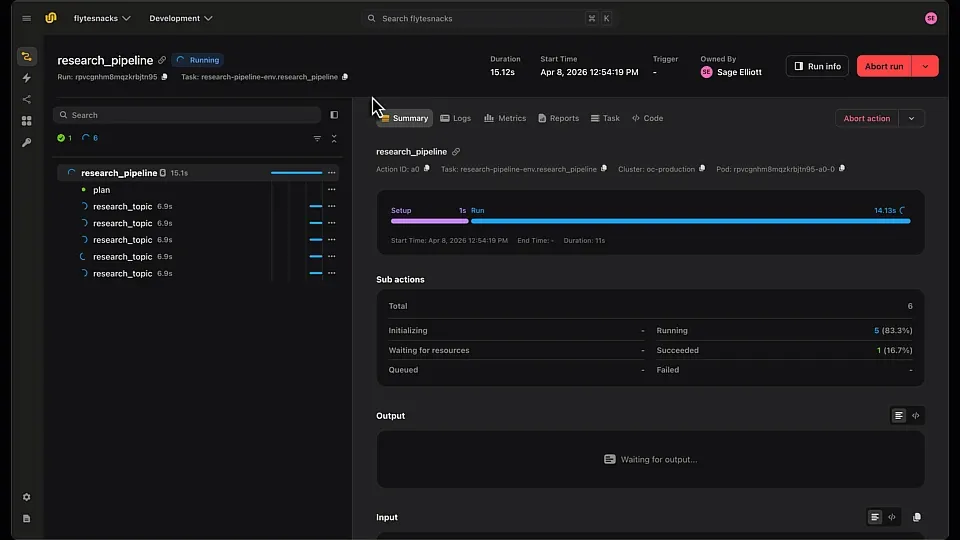
Bringing transparency and control to every stage of your model and app lifecycle
Adding observability to LLM and RAG applications is like adding a test suite to your codebase. It’s not just helpful, it’s foundational. Just like tests that help catch bugs and ensure reliability in traditional software, observability gives us a window into how our models behave in the wild.
With LLMs, things can get a little messy — they’re powerful, but also non-deterministic. That’s why it’s so important not to treat them like black boxes. If something goes wrong (and it will), we need to be able to trace it back to the source. Observability gives us that power, helping us connect model behavior to real causes, uncover hidden insights, and ultimately build more reliable AI systems.
With Union.ai, you can serve models and applications on your own infrastructure with full control over how they’re deployed and scaled. Now, with built-in support for Arize, an AI agent observability platform, you can go a step further: gain visibility into key signals like model latency, quality of generations, and user feedback, so you’re never in the dark about how your app is performing.
We’ll start by walking through how to configure tracing and why it’s important.
Tracing
Tracing, as the name suggests, helps you follow the flow of your model and application making it easier to understand what’s happening under the hood. It’s especially helpful for debugging and for getting a clear picture of how inputs move through your system and what responses come back. In RAG applications, tracing also reveals which documents the system considers based on the input query, how it generates embeddings, and how each step contributes to the final response.
Let’s take a simple example. Say you’re hosting the DeepSeek Qwen 1.5B model using Union Serving and want to enable tracing. With Arize or their open-source observability tool, Phoenix, it’s easy to get started, thanks to built-in auto-instrumentation.
Want a direct link to your traces dashboard? You can add an `ArizeConfig` or `PhoenixConfig` to include a UI link that takes you straight to the relevant traces in just a click.

Union.ai hosts both the model and a Gradio app that calls the model’s endpoint. To ensure your setup is production-ready, Union Serving offers several helpful features including support for secrets, model streaming, autoscaling, and local artifact caching to avoid network overhead. You’ll first need to cache your model from Hugging Face, which saves it as a Union artifact. Then, provide the artifact URI to the `VLLMApp` app spec.
In the Gradio app, we configure a few headers and initialize an instrumentor. Once that’s done, you should start seeing traces show up in the Phoenix dashboard giving you visibility into requests, responses, and overall app behavior.
Union Serving also supports defining FastAPI endpoints natively. You can use the `lifespan` event to register your tracer and initialize the instrumentor.
Next, let’s look at Evaluations.
Evaluation
Evaluation helps you assess how well your models and RAG or agentic apps perform against expected outcomes. It can be done in two ways: offline and online.
In offline evaluation, you typically use a fixed set of test queries and compare the model’s responses to expected outputs. For example, you might use an LLM-as-a-judge approach, where another language model scores the quality, relevance, or factual accuracy of responses based on a rubric you define. This is especially useful for comparing different versions of prompts or model variants before deployment.
In online evaluation, you measure performance in real-time on live traffic. You might schedule periodic evaluations using production data and have an LLM assess responses for correctness or hallucinations.
Both evaluation modes are complementary: offline gives you confidence before going live, and online helps you maintain and adapt performance in production.
With Union.ai, the delta between online and offline evaluation is small, thanks to native support for scheduled runs. Even an offline evaluation task can become an online evaluation if you schedule it to run at regular intervals, say, every few minutes.
You can use Union tasks to set up evaluations with Arize. Just define your evaluation logic inside a task, and you can run it locally or on a remote cluster, depending on whether you're running it ad hoc or on a schedule.
You can also use a self-hosted Union.ai model for evaluations. By defining a launch plan, you can set up a schedule to automate this process.
This setup runs evaluations at a specified cadence (ideally every few minutes for online evaluation), and the results are logged directly into Arize/Phoenix for easy monitoring and analysis.

Final thoughts
We explored how Union.ai offers first-class support for integrating Arize observability into your models and apps. This unlocks transparency at every stage of the model and app lifecycle. With the ability to trace and monitor model behavior in real-time, you can quickly identify and address issues, ensuring your models and applications are both reliable and performant.
Say you notice in one of the traces that your model is hallucinating, returning information that isn’t grounded in your source data. With that insight, you can take targeted action: refine your prompts, improve your retrieval strategy, filter out noisy or irrelevant documents, or even fine-tune the model with higher-quality examples. By closing the loop between observability and iteration, you can continuously improve the quality of your outputs.
You can find detailed documentation on integrating Arize with Union.ai in the Union docs. In the near future, we’ll also explore how to set up Guardrails to ensure your models and apps stay within desired performance and behavior thresholds.
Interested in learning more about Union.ai? Let’s talk!