<div class="text-align-center">This article was originally posted on our Substack, The AI Loop.</div>
<div class="button-group is-center"><a class="button" target="_blank" href="https://unionailoop.substack.com/">Follow The AI Loop</a></div>
In March, Mercor, a $10 billion AI startup that supplies training data to Anthropic, OpenAI, and Meta, confirmed it had been breached. The attackers claimed four terabytes of data: Slack logs, internal ticketing systems, videos of conversations between Mercor’s AI systems and contractors, and potentially datasets tied to its customers’ most sensitive model development work.

Mercor didn’t get phished. Their engineers didn’t misconfigure an S3 bucket. They used LiteLLM, a wildly popular open-source library for connecting applications to AI services downloaded millions of times a day. A hacking group had already planted malicious credential-harvesting code inside it. Mercor was, in their own words, “one of thousands of companies” affected.
One library. Thousands of victims. How could this happen?
It’s not like Mercor was careless. They were operating with the same implicit assumption most AI teams make: your responsibility for security stops when data leaves your cloud.
That assumption is wrong, and the cost of getting it wrong keeps going up.
Pop quiz! What’s better - option 1 or option 2?
Imagine you have a safe. Inside it: customer PII, training data, proprietary model weights, API credentials, internal comms. Everything your company runs on.

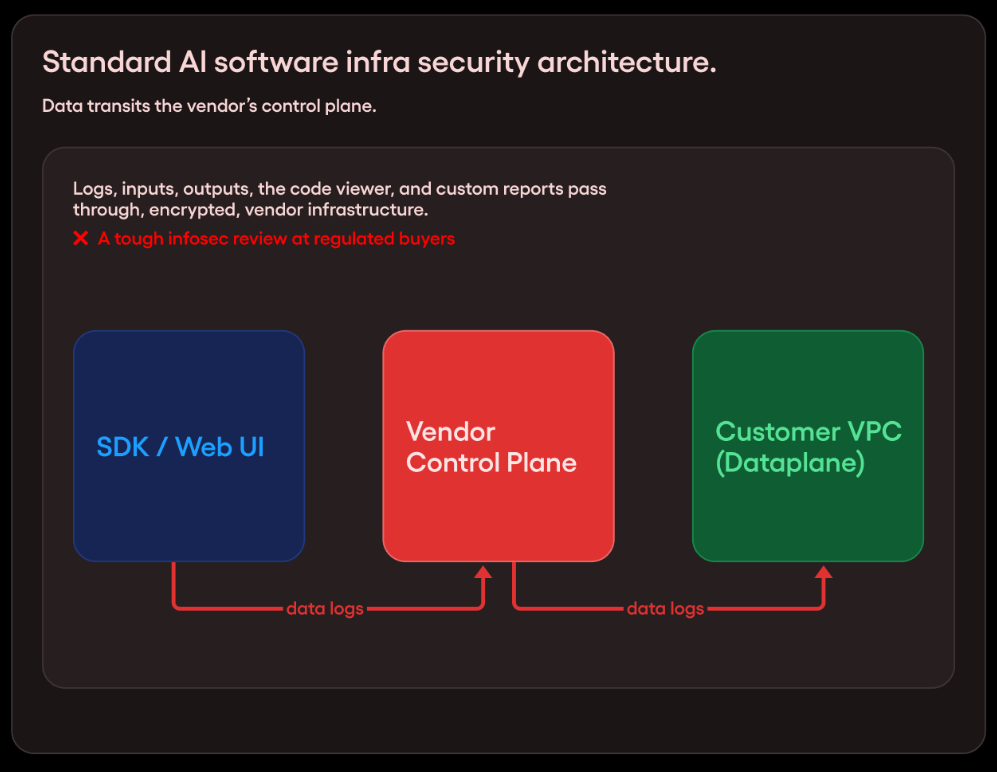
Now imagine two options. In the first, the safe sits in your office. You control who enters the building, when the maintenance crew comes in, and which vendors get temporary access with a supervised key. In the second, you move the safe to your vendor’s office. Their building. Their staff. Their security policies. Their breach surface.
Which would you choose?
The safe analogy maps directly to a real architecture decision embedded in most AI stacks today, made implicitly, at the library level, with no security review attached.
When your training data transits a vendor’s cloud infrastructure, when your inference requests pass through a managed API layer, when your pipeline orchestrator runs on someone else’s compute, your safe is in their office. You’re trusting that their walls are thick enough and their staff is careful enough and their third-party integrations are all clean.
Recent history suggests that’s a lot of trust.
The Breach Catalog Is Getting Long
Mercor is the latest entry in a pattern that’s been compounding for two years.
The Salesloft-Drift incident in August 2025 is another example. Attackers didn’t break through a firewall or exploit a zero-day. They used stolen OAuth tokens from a single AI chatbot integration (Drift) to move laterally into the environments of over 700 organizations. The access looked completely legitimate. The activity blended into routine SaaS traffic. By the time anyone noticed, the blast radius was enormous.
A few months later, OpenAI confirmed a data exposure traced back to a breach at their analytics vendor, Mixpanel. Not OpenAI’s infrastructure. Their vendor’s. Names, emails, organizational data: exposed, because a third party had access to data that transited their systems and their security posture wasn’t OpenAI’s to control.
In all of these cases, attackers didn’t break down the front door. They walked through the vendor entrance, or in Mercor’s case, the library import.

Verizon’s 2025 Data Breach Investigations Report quantified it: third-party involvement in breaches doubled year over year. According to a March 2026 survey of 500 CISOs by Vorlon, 99.4% of enterprises experienced at least one SaaS or AI ecosystem security incident in 2025. One in three experienced a security incident involving AI agents specifically.
Your attack surface is no longer just your infrastructure. It’s the full graph of every vendor your infrastructure touches, including every dependency those vendors rely on.
The answer? Zero Trust architecture
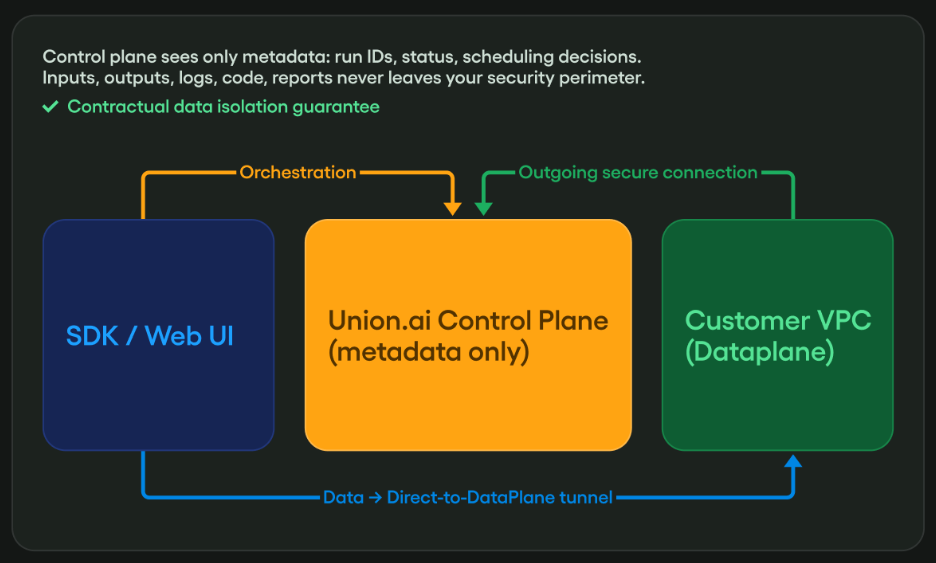
Zero Trust is emerging as the answer to this new security anxiety brought on by AI infrastructure vendors. At its core, it’s a design philosophy that says: no user, device, service, or vendor should be trusted by default, regardless of where they sit relative to your perimeter.
The strongest security posture is not encryption, it’s when the data isn’t there in the first place.
Traditional security was built on the castle-and-moat model, with a hard outer shell and a soft, trusted interior. Once you were inside the walls, you could move around freely. Zero Trust treats every connection as if it’s coming from outside the walls, because increasingly, it is.
For AI teams specifically, this cashes out in a few concrete ways:
Identity over location. A service running inside your VPC isn’t inherently trusted just because of its network position. Every service needs to authenticate and authorize every request, including internal ones.
Least-privilege access. Your AI/ML pipeline doesn’t need read/write access to your entire data lake to run a training job. Scope credentials to exactly what each workload requires. This is what separates a bad day (a compromised token) from a catastrophic one (full data exfiltration).
Keep your data in your building. Encryption in transit is table stakes, but it’s not the real protection. An encrypted file in someone else’s office can still be stolen when the office is broken into. Sensitive data, especially training data and model artifacts, should not transit vendor infrastructure in the first place. Design your pipelines so the data stays where you control it. When transit is unavoidable, minimize what moves and treat every byte that leaves your environment as a potential exposure.
Audit everything. Zero Trust assumes breach. That means logging every access request, every data movement, every credential use, so that when something does go wrong, you have a trail to follow instead of a mystery.
Vendor data isolation. The most overlooked principle for AI teams: if you have to share data with a vendor, minimize scope and monitor aggressively. Your vendor’s breach surface is your breach surface. Be deliberate about what you’re putting in their office.

Why This Matters More for AI Infrastructure
AI systems have a few properties that amplify security risk beyond what traditional software faces.
First, they’re data-hungry by nature.
Training pipelines, feature stores, data preprocessing layers, they all move large volumes of sensitive data through multiple systems. Most of that movement is automated and hard to audit.
Second, the tooling is new and the security posture is still catching up.
LiteLLM is downloaded millions of times a day by teams who reasonably assume a popular, widely-used library is safe. The window between “widely trusted” and “actively exploited” can be very short. When you adopt a new AI framework, you inherit whatever security decisions its maintainers made, and whatever threat actors have already found.
Third (and most important), AI systems are increasingly agentic.
An agent with access to your file system, email, and internal APIs is a potential foothold for automated lateral movement. Compromise the agent, and you’ve compromised everything it can reach.
This is part of why frontier AI companies are treating security as an architectural constraint rather than a layer bolted on afterward. Think about how Anthropic is handling Mythos, Fable, and Project Glasswing.
So as builders decide whether and which outside tools can access their data, they need to be honest about what they’re doing: they’re making tradeoffs between capability and attack surface.
What Good Looks Like
Zero Trust for AI infrastructure requires real intentional design, but it’s achievable.
It means choosing AI infrastructure (especially when considering AI runtimes, orchestration and execution layers, etc.) that…
- runs on your secure cloud without needing deep access to your data to deliver value
- supports workload identity, encrypted secrets management, and granular access controls
- operates your pipelines in environments where you govern the compute and the data movement, rather than having your data transit someone else’s infrastructure by default
- provides audit trails that tell you what ran, what it accessed, and what it moved
Vendors aren’t the enemy, but their architecture can be vulnerable and you don’t have visibility into it. You can’t outsource your threat model. If your data is in their hands, your vendor’s breach is your breach.
Keep your data on your own secure cloud. Keep the safe in your building.
Have thoughts on Zero Trust for AI systems, or a security story from the field? Drop it in the comments, we read them all.
It takes a community to build a community. Please share this article if you liked it!
<div class="button-group is-center"><a class="button" target="_blank" href="https://unionailoop.substack.com/p/the-backdoor-into-your-ai-stack?utm_source=substack&utm_medium=email&utm_content=share&action=share">Share</a></div>
Hey, we’ve got some announcements!
Try the Flyte 2 devbox
The Flyte 2 devbox is a great way to demo a simplified version of Union.ai on your local machine.
The devbox is a lightweight local cluster that runs on your machine with Docker. It includes the Flyte 2 UI, scheduler, and object store, so you can test remote execution without deploying to a real cluster.
Upcoming virtual sessions and workshops:
7/9 - LLM fine-tuning with GRPO
In this hands-on workshop, we’ll fine-tune an open-weight LLM with GRPO using Hugging Face TRL, write reward functions that actually shape behavior, and deploy the result behind a simple UI. The whole pipeline runs on Flyte 2/Union, so data prep is cached, runs are reproducible and recoverable, and the same code scales from a laptop to a multi-node cluster without rewrites.
By the end, you’ll have a working GRPO-trained model and a reusable RL pipeline you can point at your next task.
→ RSVP to attend or get the recording
7/14 - Building Code Mode Agents
In this hands-on workshop, we’ll build a code mode agent that writes and executes code to call tools, then deploy it behind a simple UI. The whole pipeline runs on Flyte 2/Union, so runs are durable and reproducible, steps are cached, and the same code scales from a laptop to a multi-node cluster without rewrites.
By the end, you’ll have a working code mode agent and a reusable pattern you can point at your own tools.
→ RSVP to attend or get the recording