
- Get started with Flyte: docs.flyte.org
- Join the community: Slack
- Make a Contribution: GitHub
- Next Event: LLM fine-tuning with GRPO
Hello everyone. I’m going to keep a variation of this intro in the first few posts. Just quick reminder of why this landed in your inbox: at some point you opted in to hear from the Union.ai/Flyte team (Likely from one of my events). I’m restarting our newsletter, it will be short, practical AI engineering tips you can actually use. I think it’s going to be. alot of fun, but if it turns out this isn’t for you, no hard feelings, you can always unsubscribe. —Sage Elliott
AI engineering tip of the week: Fan Out Tasks Like a Pro with Map Tasks
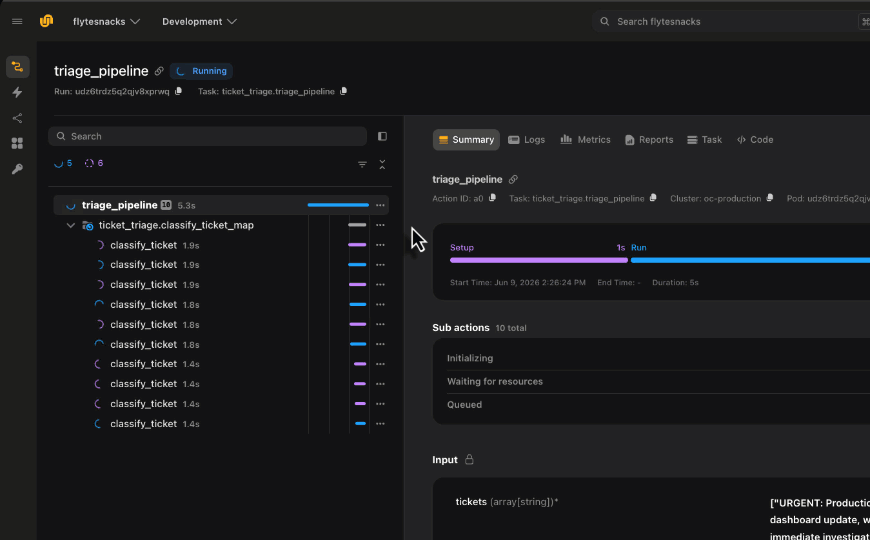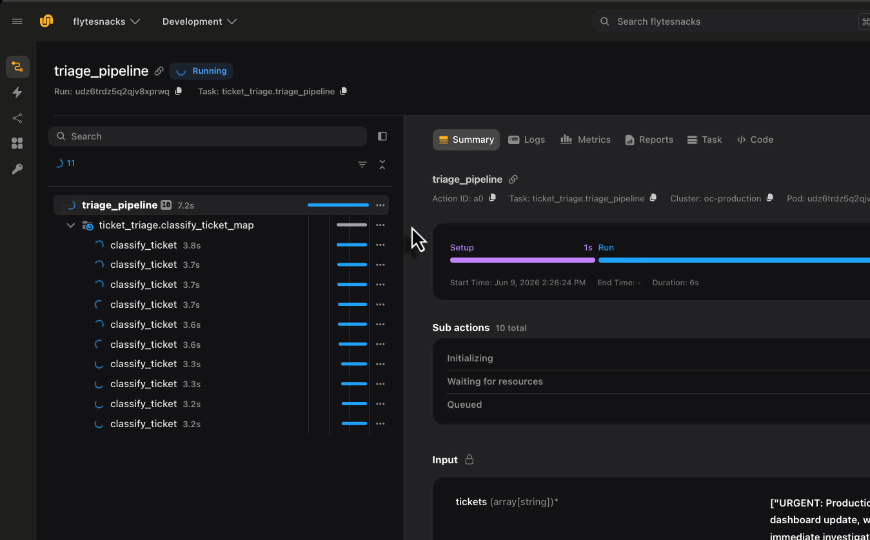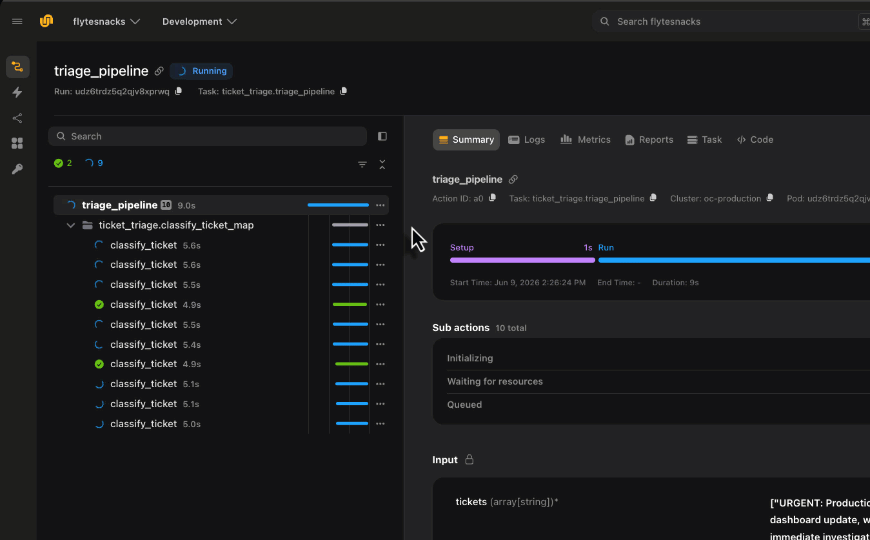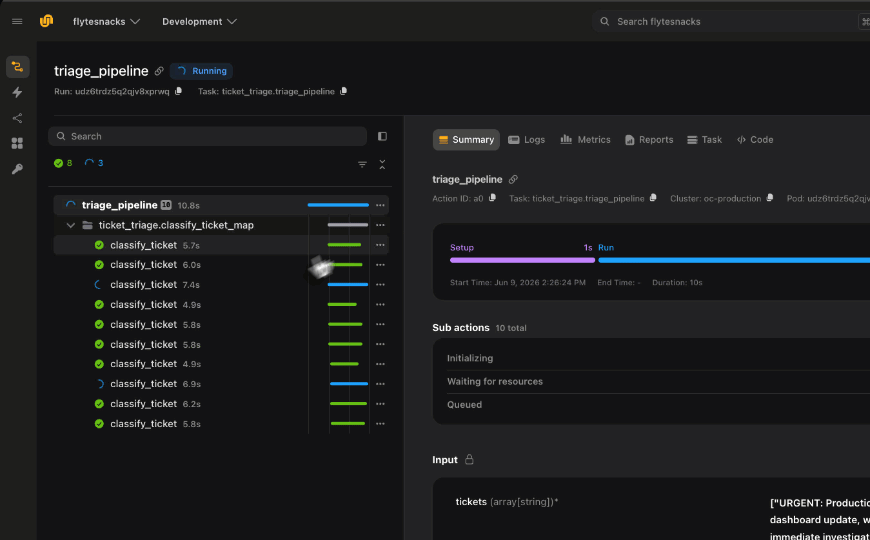
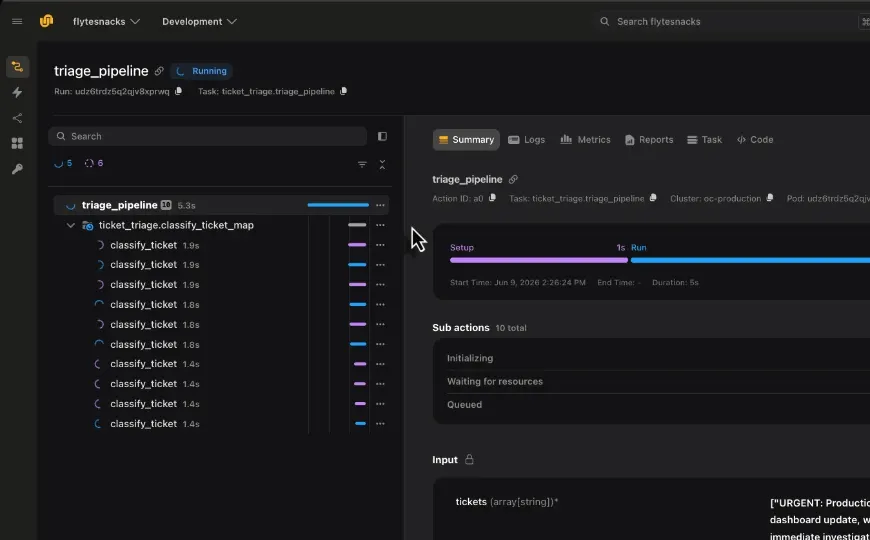
Need to run the same task across 100 datasets, 1,000 hyperparameter combos, or a batch of images? Don’t write a for-loop that runs them one at a time. Use flyte.map() to fan out work across your cluster in parallel.
flyte.map() takes a task and an iterable of inputs, then distributes the work. Each item gets its own container, its own resources, and its own retry logic. It’s like map() in Python but distributed across your infrastructure.
Basic example: process a batch in parallel
Each call to `process_item` runs as a separate Flyte task. If one fails, the rest keep going (when using `return_exceptions=True`).
Control concurrency so you don’t blow up your cluster
Don’t want to launch 10,000 tasks at once? Set a concurrency limit:
Now at most 50 tasks run simultaneously. Flyte queues the rest and feeds them in as slots open.
When to use map vs asyncio.gather
`flyte.map()` is best when:
- You want a built-in concurrency limit `(concurrency=N)`
- You want to stream results with `async for`
- You need to work with sync (non-async) tasks
- You have a clear “same task, many inputs” pattern
`asyncio.gather()` is best when:
- You need to compose different tasks together in parallel
- You want more flexible error handling and control flow
read more on controlling parallelism: https://www.union.ai/docs/v2/flyte/user-guide/task-programming/controlling-parallelism/
See what’s happening in the Flyte Community:
Latest from the blog
- LangGraph on Flyte: Orchestrate the Logic & Scale the Compute - Read on Union.ai
- Announcing Zero Trust Security Architecture - Read on Union
- How We Kept Python and Got Our Speed from Rust - Read on Union
Recent talks & recordings
- Talk Recording: Putting Resilient AI Agents in Production - Watch on Youtube
- Workshop Recording: Build Research Agents That Don’t Break: LangGraph + Flyte - Watch on YouTube
- LLM fine-tuning with LoRA & QLoRA - Watch on YouTube
- Fine-Tuning BERT for the Unstructured Data You Actually Have - Watch on YouTube
Upcoming events
- July 9th: LLM fine-tuning with GRPO - RSVP on Luma
- July 14th: Building Code Mode Agents - RSVP on Luma
- July 15th: Seattle AI, ML, and Computer Vision Meetup at Union HQ - RSVP on Voxel51
Releases & updates
- Flyte 2 OSS: Backend Devbox and Reimagined UI - Read on Union
- June’s release brought first-class agents with memory and tool approval, SDK-authored MCP servers, backoff retries and per-attempt timeouts, multi-pod log streaming, and beta queues and events APIs. - Read the Release notes
From the community
- July 15th: Seattle AI, ML, and Computer Vision Meetup - RSVP on Voxel51
- AI Book Club: Agentic Architectural Patterns for Building Multi-Agent Systems - RSVP on Luma
That’s all for this week! —Sage Elliott


