

Agents don't just fail at the semantic layer. They fail at the infrastructure layer too, and that’s what prevents them from succeeding in production.
You've built an agent. You optimized its prompts, engineered its context window, built an eval harness, and it works beautifully in development. Then you ship it to production and watch it fail in ways your evals never anticipated.
Not because the LLM hallucinated. Not because a tool call was malformed. Because a spot instance got preempted. Because a container ran out of memory mid-run. Because a network timeout wiped the agent's state after 200 steps of hard-earned work.
This is the agent infrastructure problem, and it's underappreciated precisely because the ML and AI communities have gotten very good at reasoning about semantic failures while remaining relatively underprepared for the infrastructure layer underneath.
After five years building and maintaining Flyte, the open-source AI/ML orchestration platform used by teams at LinkedIn, Stripe, Spotify, and Mistral, I was invited to give a lecture for the MLOps community on this subject.
50% of workflow failures aren’t being solved autonomously
Most agent evaluation frameworks test semantic correctness: Does the agent answer the question accurately? Is it hallucinating? Are the tool-call arguments well-formed? These are the right questions to ask, and the field has made real progress here.
But there’s an alarming gap in how we address infrastructure-caused failures. These make up about 50% of all workflow failures.
Evals typically don't test what happens when:
- A container runs out of memory halfway through a multi-step pipeline
- A spot instance is preempted after 150 of 200 planned steps
- A network partition interrupts a sub-agent call and the retry loses the accumulated context
- The root agent process crashes, and the entire run has to restart from scratch
Agents similarly tend to handle the logical and semantic failure modes well (e.g., retry on bad tool output, rephrase on ambiguous response, escalate on repeated failure). But they don't often directly handle infrastructure-level failures, because those failures aren't represented in the agent's context. The agent simply doesn't know they happened.
The key insight: infrastructure failures are only unrecoverable if the agent can't see them.
If you surface an OOM error as a structured exception, pass it back into the agent loop with full context, the agent can respond to it by requesting more memory, adjusting its resource config, and retrying. The failure becomes an input rather than a termination condition.
We call this using infrastructure-as-context. And this infrastructure-awareness is how you can solve the 50% of failures caused by infrastructure alongside the semantic 50%. With this scope, our AI, ML, and agentic workflows become resilient enough to self-heal from most failures.
Three building blocks for durable, self-healing agents
Before getting to design principles, there are three foundational primitives that make durable agents possible. These are core to Flyte’s data model, but any serious agent infrastructure needs an answer to each of them.
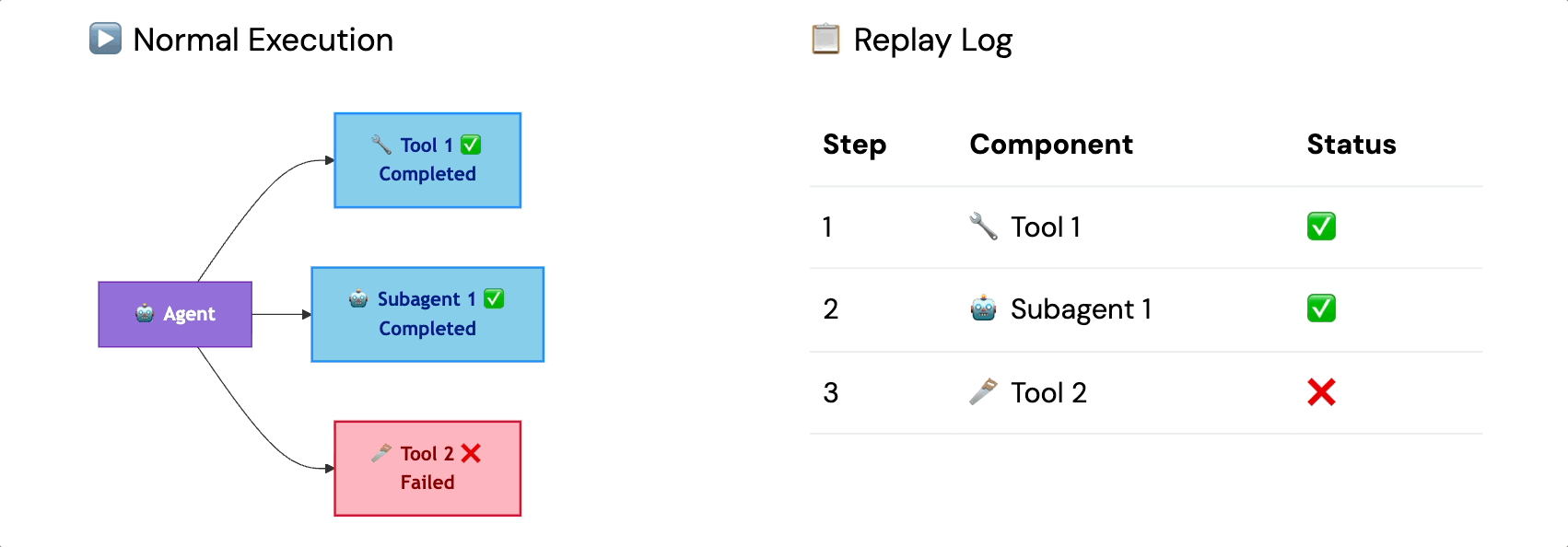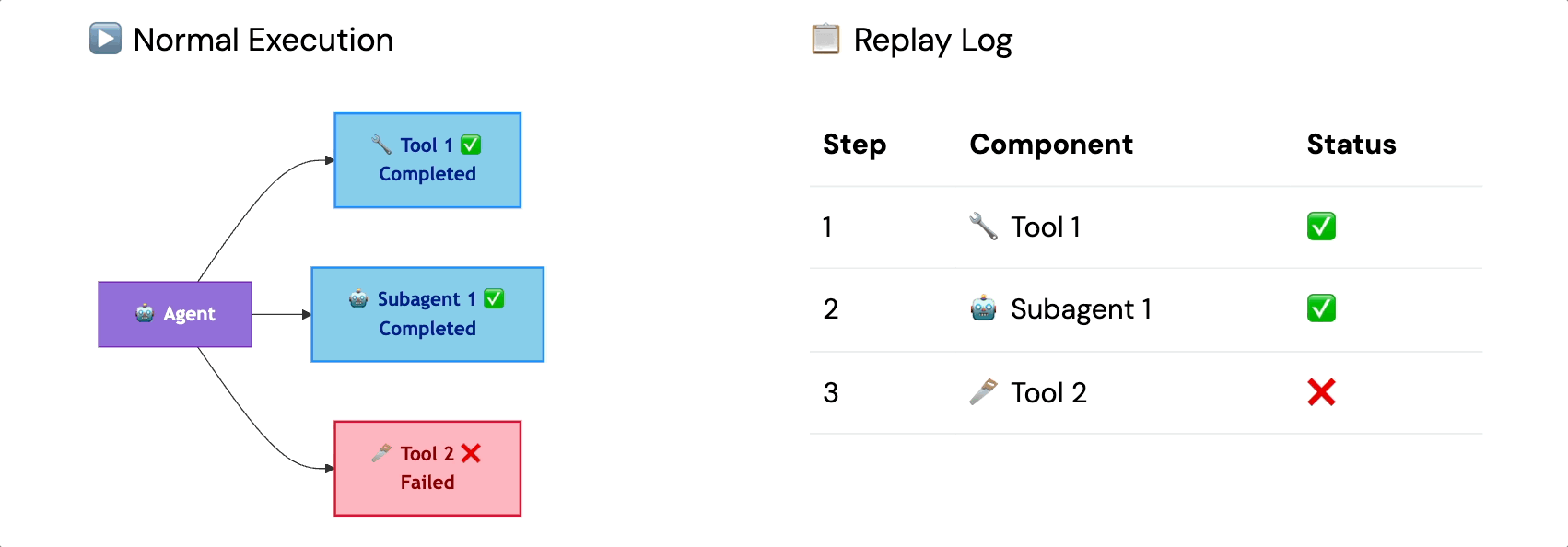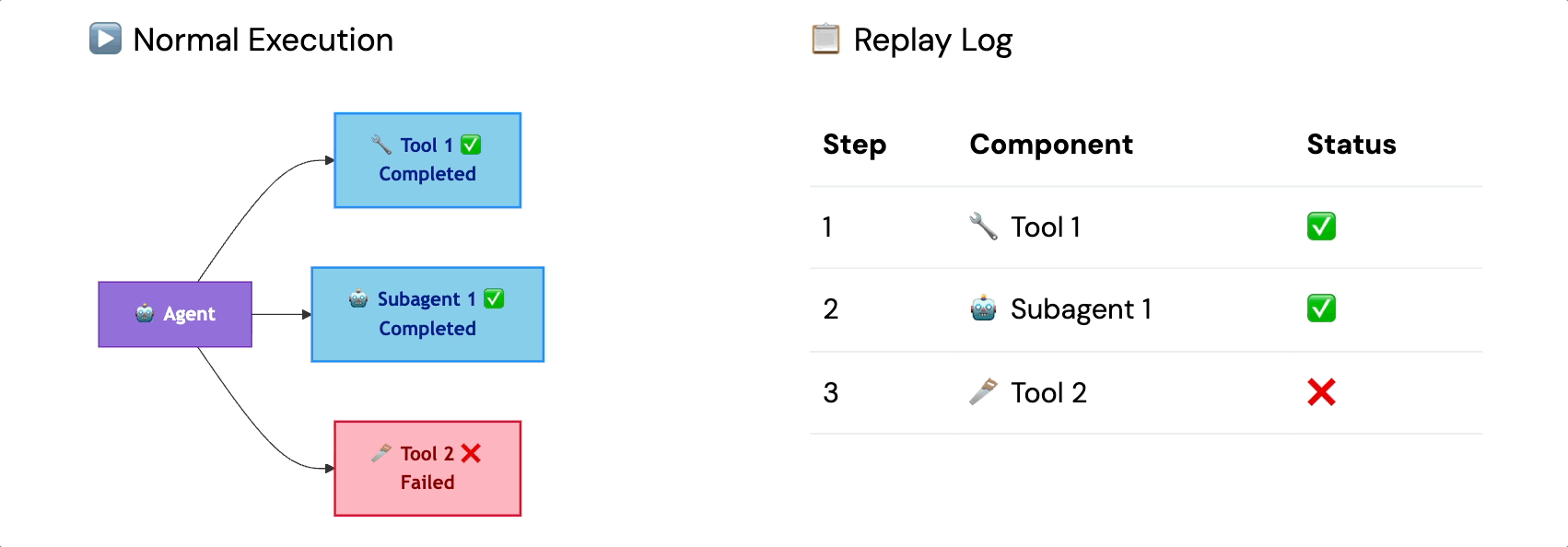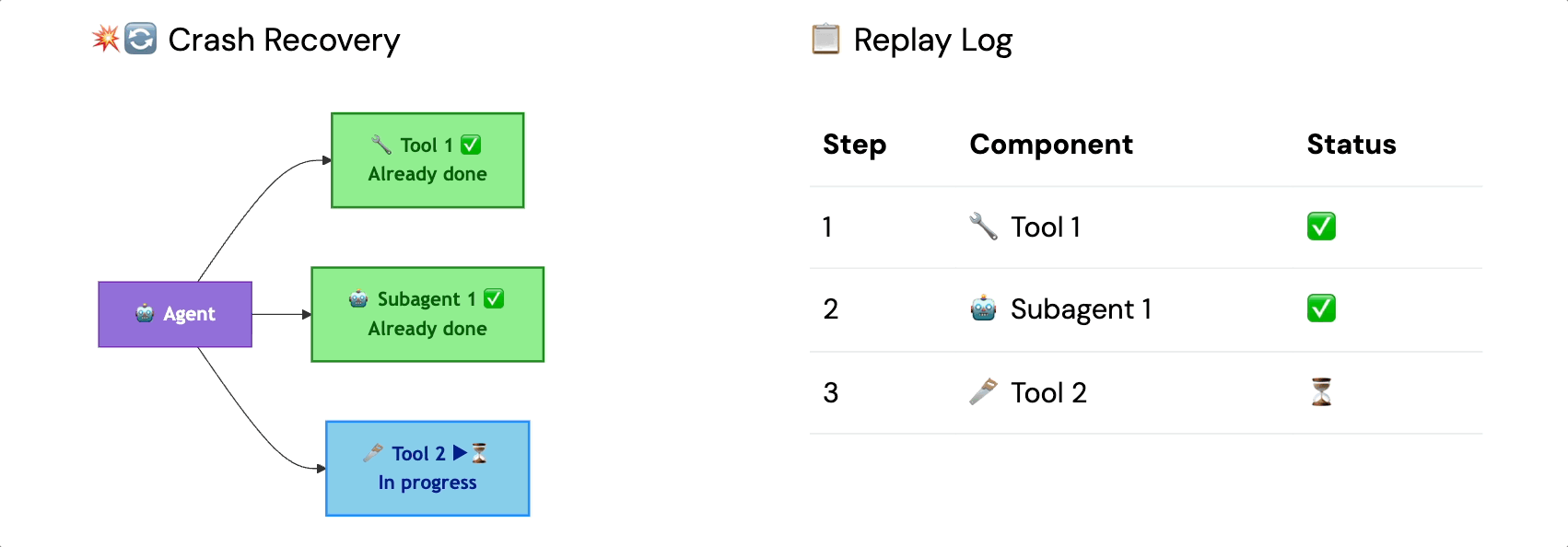
1. Replay Logs (Per-Run Checkpointing)
A replay log records the state of an agent and its subtasks at a granular level at each step. If the agent completes tool call one and sub-agent call one before crashing on tool call two, the replay log means it resumes from tool call two, not from scratch.
At the scale of 200-step runs, this is the difference between spot instances being a cost optimization versus a liability.
Think of it as a micro-cache scoped to a single run. You take for granted that any network or system outage will result in the agent picking up exactly where it left off.
2. Global Caching (Cross-Run Deduplication)
Where replay logs are scoped to a single run, global caching is shared across all agents and all runs. If an agent calls the same deterministic tool (e.g., a web search or a database read) with the same inputs, the result can be cached and reused across runs.
This has a subtle but important design implication: you can be selective about what you cache. A research step that fetches data should be cached. A synthesis step where you want the LLM to exercise some creativity probably shouldn't be. Global caching lets you tune the determinism-creativity tradeoff at the step level.
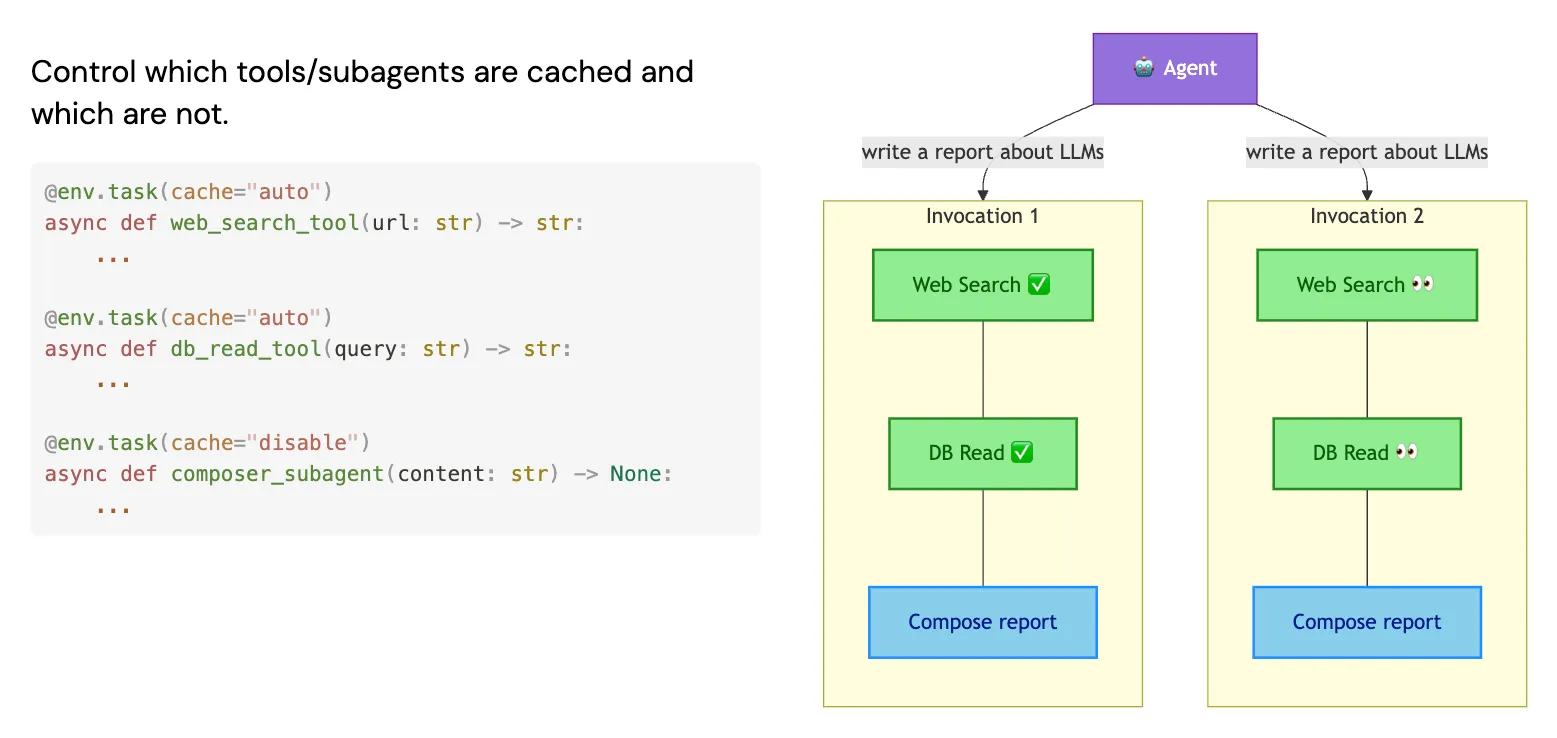
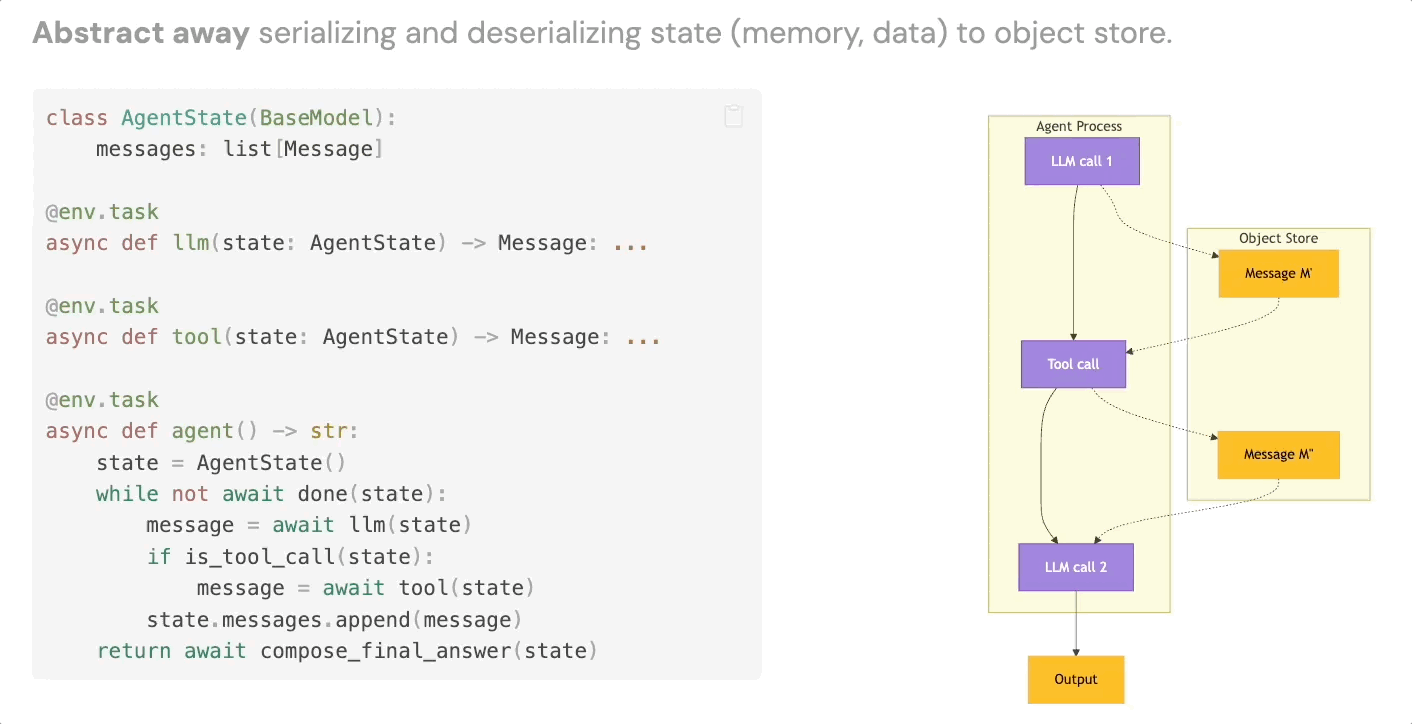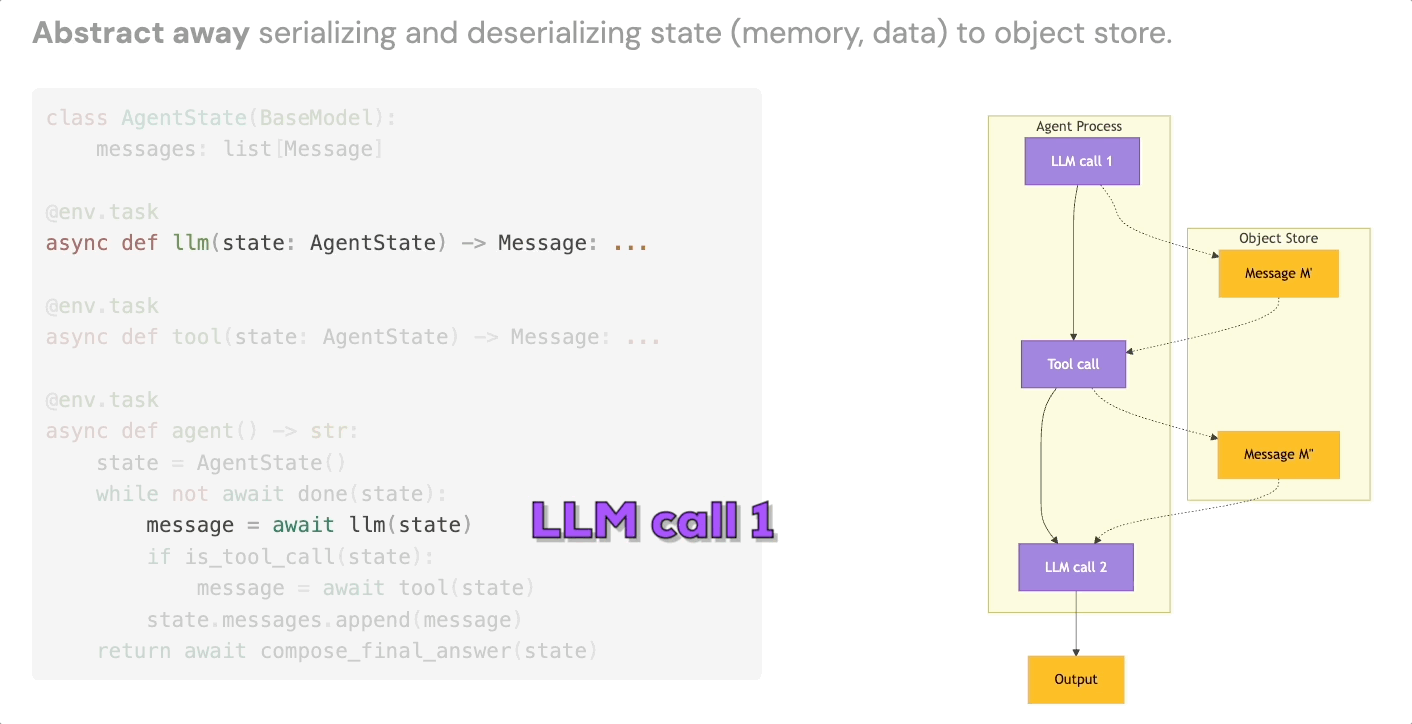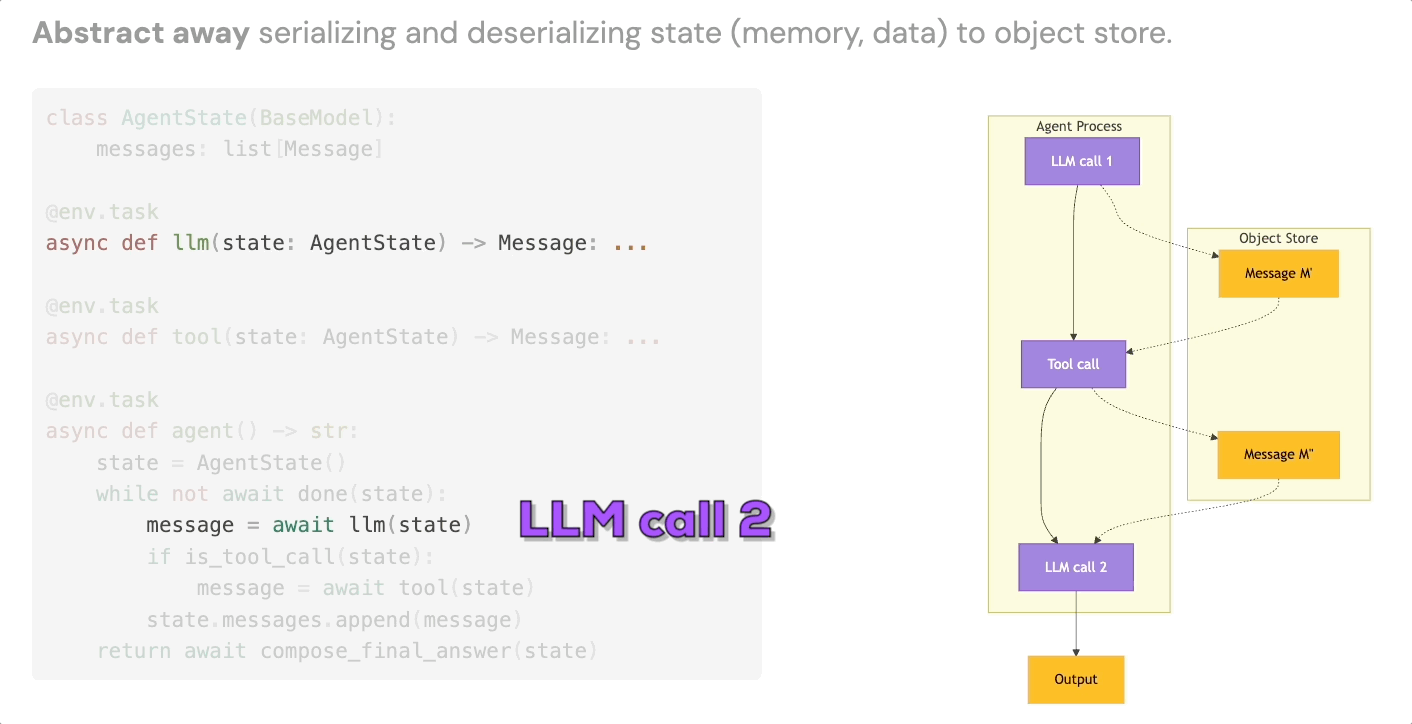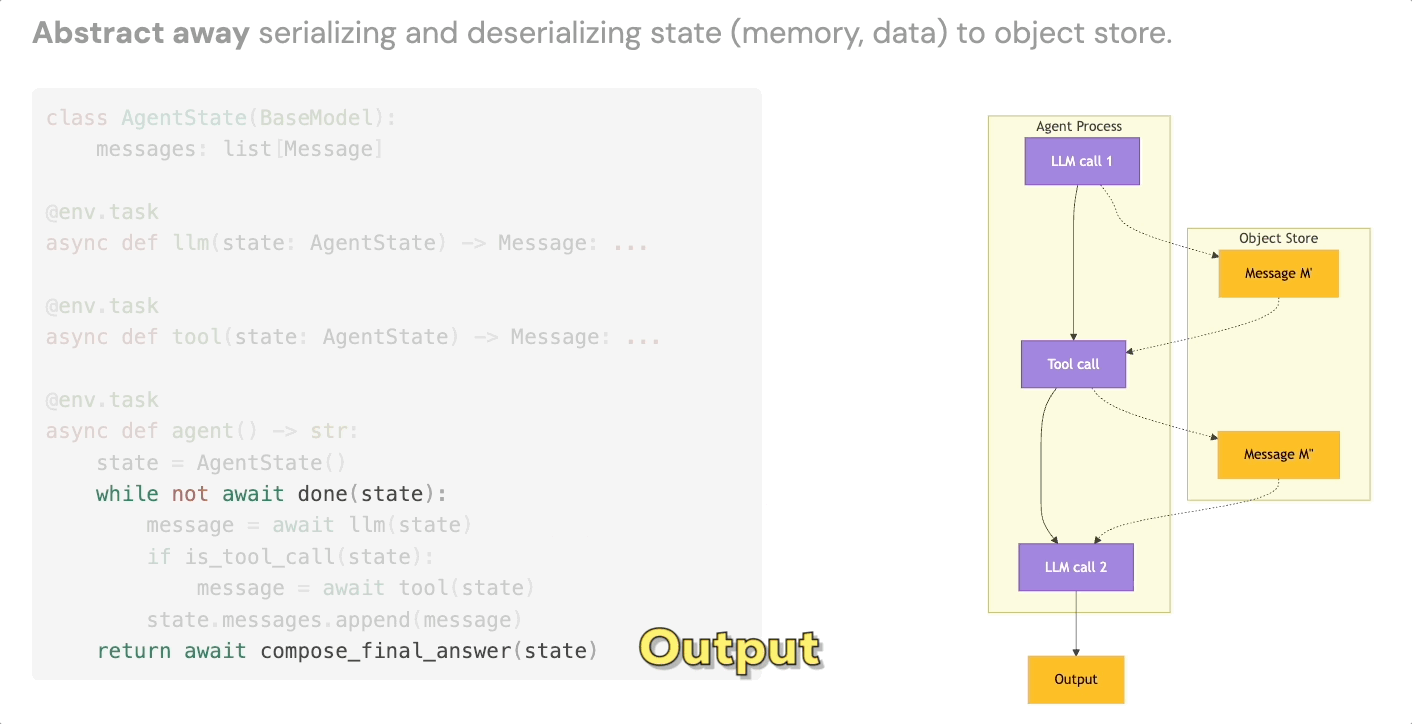
3. Intermediate State Persistence
The third building block is automatic serialization of agent state at each step. Every LLM call, every tool result, every intermediate output gets persisted to object storage, without you writing any serialization or deserialization code.
This gives you data lineage for free. It means agent memory survives infrastructure failures. And it means that failed runs become inspectable artifacts rather than black boxes – useful both for debugging and, more interestingly, as training data or additional context for future runs.
Six design principles for making agents production-grade
With those building blocks in place, here are the design principles we've distilled from building agents at Union.ai and helping customers do the same.
1. Use Plain Python (or Whatever Language the LLM Knows Well)
Frameworks are fine, but the core agent loop should be expressible in a general-purpose language. You get loops, fan-out, conditionals, try/except, async. All the programming constructs that humans and LLMs alike understand well.
More importantly: exceptions are the perfect delivery mechanism for failure context. When an OOM error gets caught as a Python exception and passed into the agent's next iteration, the agent has everything it needs to reason about the failure and respond to it. This is the mechanism that makes infrastructure-as-context work in practice.
2. Provide Functional Durability Hooks
Assuming you're using functions or class methods for your agent's tool calls and sub-agents, decorators or wrappers can add durability like checkpointing, tracing, and state persistence, without modifying the underlying logic.
In Flyte, this looks like annotating a function with task metadata: its container image, resource requests, IAM role, caching behavior. The function itself is unchanged. You get container isolation, crash-proof guarantees, and per-step lineage as side effects of the annotation.
3. Make Failures Cheap
The goal isn't to eliminate failures. Failures are inherently part of non-deterministic AI processes. The goal is to make recovery so fast and so cheap that failures stop mattering.
With replay logs and intermediate state persistence in place, a crashed agent picks up mid-run rather than restarting. With global caching, you don't re-pay for expensive tool calls. The feedback loop from failure to recovery shrinks from minutes (or losing the entire run) to seconds.
An underappreciated benefit: failed runs become training data. The full execution trace — what the agent tried, what failed, how it recovered — is available as a structured artifact. You can query it out-of-band to build fine-tuning datasets. You can feed it back inline as additional context for the current run.
4. Provide Infrastructure as Context
This is the core principle. When an agent's inner loop surfaces infrastructure failures as structured, inspectable exceptions, the agent can reason about them directly.
An out-of-memory error is a signal that the agent's resource request was undersized. Pass that signal back into the loop, and the agent can provision more memory and retry. A missing dependency becomes a prompt to update the dependency spec and re-run.
This pattern unlocks a class of self-healing behaviors that pure semantic reasoning can't provide, because semantic reasoning doesn't have access to what happened at the infrastructure layer.
5. Provide Agent Self-Healing Utilities (Sandboxes)
Not all failures can be handled through structured resource adjustments. Sometimes the agent needs to write and execute code to solve a problem its static tool belt can't handle. Two types of sandboxes are useful here:
Code-mode sandbox (orchestration-only): The agent writes Python code that's executed in a restricted environment, without arbitrary I/O, network calls, or extra imports. The agent orchestrates its existing tools through code rather than through structured tool calls. This reduces the context overhead of tool-call formatting and enables a tight error-iteration loop: the agent writes orchestration code, it runs, fails, and the agent fixes it all within the inner loop.
Stateless code sandbox (general-purpose): A one-shot execution environment where the agent can write arbitrary code, including third-party imports and limited I/O. This is for the long tail of requests that fall outside the agent's predefined tool set. The agent writes the code, it runs end-to-end, and produces output. The agent can even write its own unit tests.
Together, these sandboxes give the agent a fallback path when its structured tools aren't sufficient, and they do so in a way that's secure and auditable.
6. Human-in-the-Loop as Final Recourse
Some failures are genuinely unrecoverable autonomously: the system prompt is fundamentally broken, the task is underspecified, the agent has exhausted its iteration budget without converging.
Human-in-the-loop is the correct final recourse to ensure durability. When the agent has exhausted its autonomous options, it should surface a clean request for additional context: upload a file, provide clarification, restate the goal. Then resume.
The key is that this escalation should be programmable and explicit, not a crash or an infinite retry loop. In Flyte, this looks like a Python call that pauses execution and awaits input, then resumes with the additional context injected into the agent state.
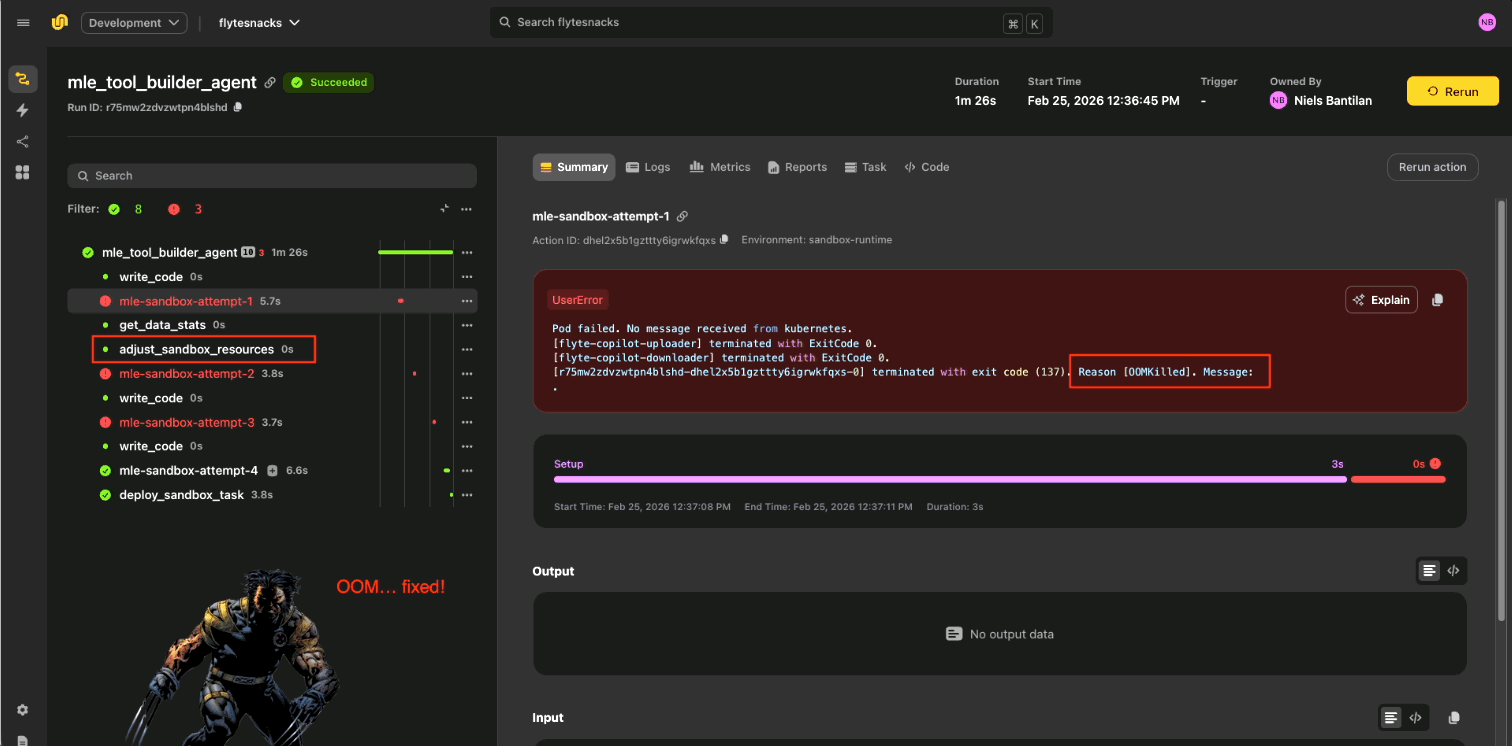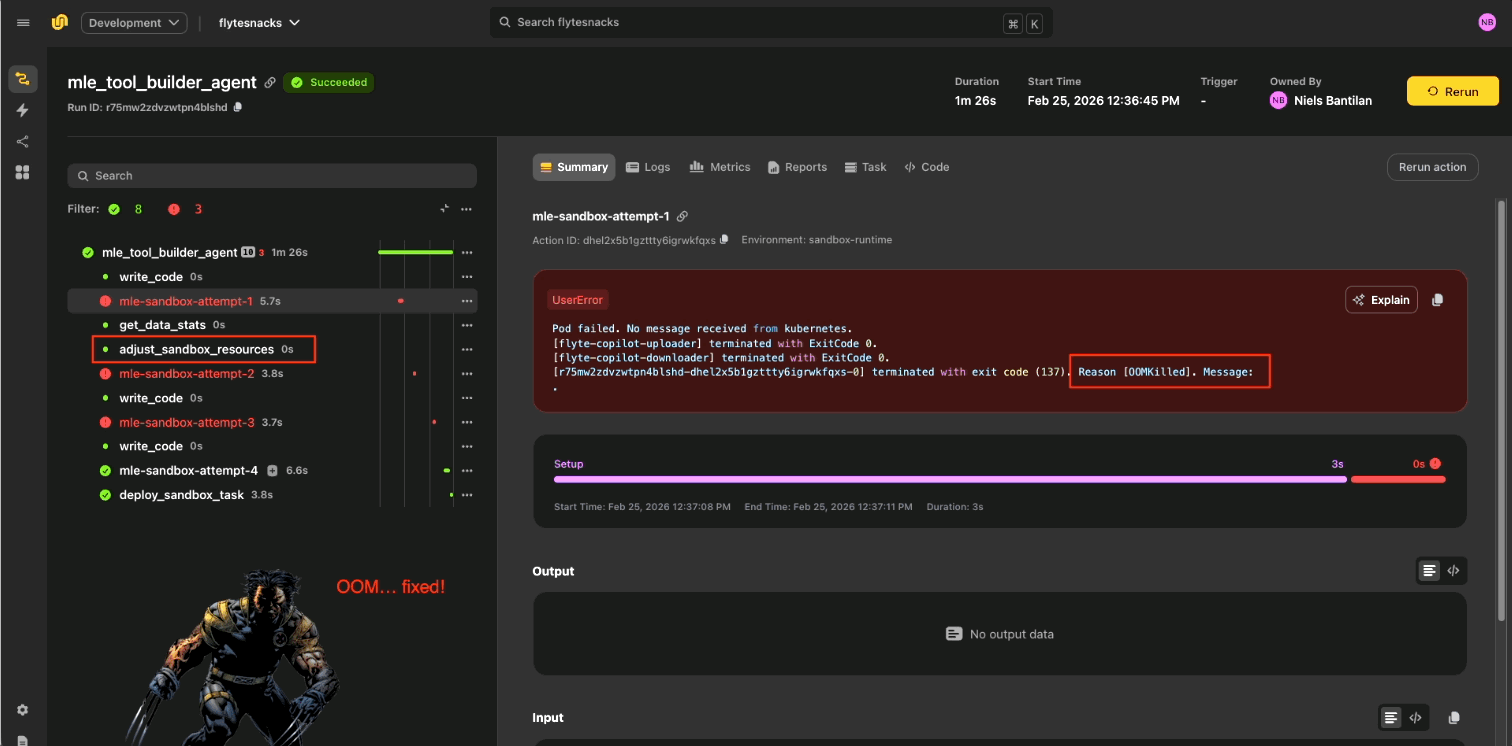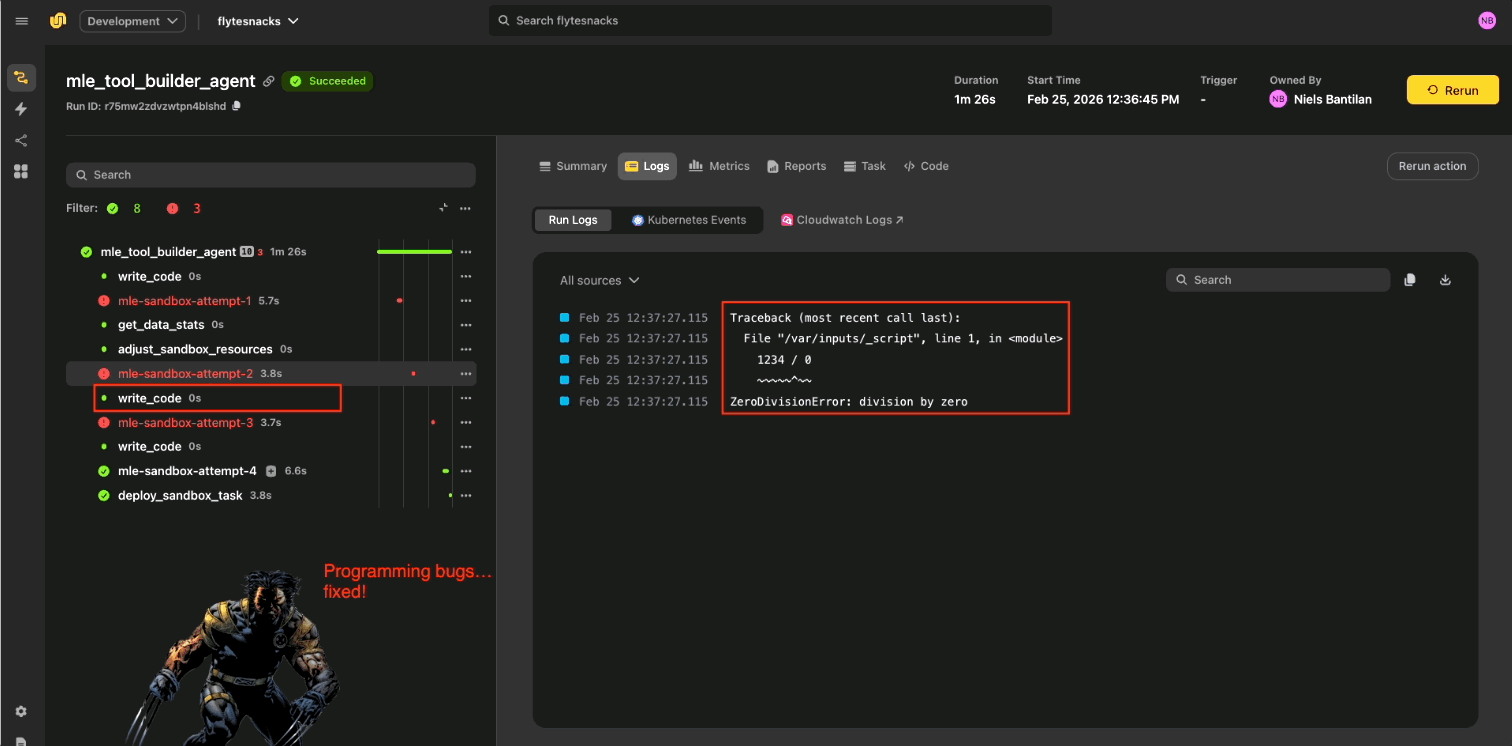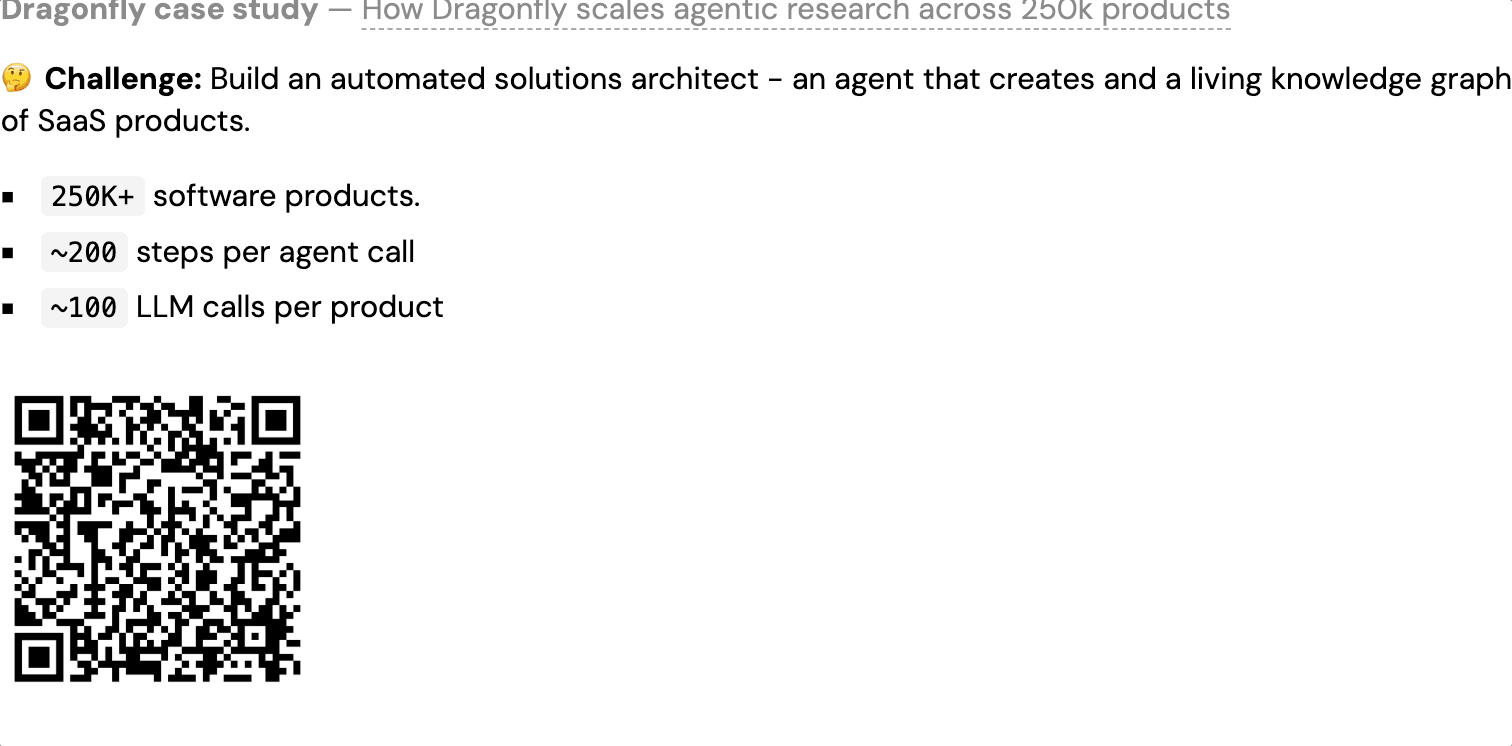
Case Study: Cutting failure-recovery time in half
The principles above become concrete at scale. We worked with Dragonfly, a deep-research SaaS product, to build an automated solutions architect — an agent that maintains a living knowledge graph of 250,000 software products.
The scale of this is worth sitting with: 200 steps per agent run, ~100 LLM calls per product, dynamic research threads whose count isn't known in advance. This isn't the kind of agent you prototype in a chat interface. It runs ambiently, populates a database, and has to be reliable enough to stake a product on.
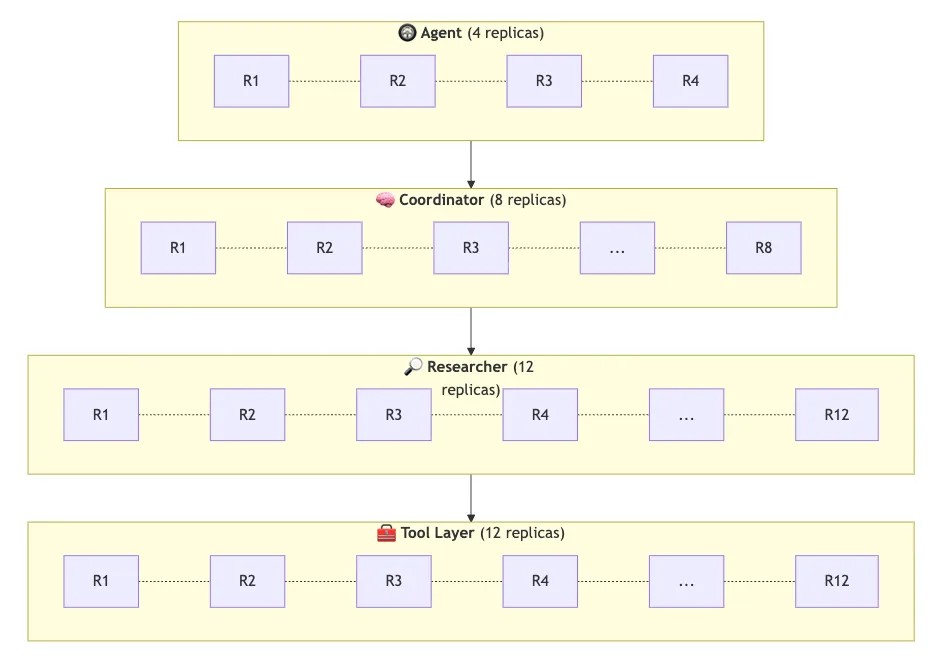
Their architecture was tiered: an agent driver with 4 replicas at the top, research coordinators with 8 replicas in the middle, individual researchers beneath them, and a tool layer with 12 replicas that each researcher could access.
A few things stood out from this engagement:
Checkpoint-based recovery made spot instances a non-issue. They used spot instances heavily to reduce costs. With per-step checkpointing, preemptions became a 2-3 second interruption rather than a lost run. The cost optimization worked without the reliability tradeoff.
Semantic convergence detection. Their coordinator layer periodically looked across all active research threads, grouped semantically similar ones, and consolidated to avoid duplicate work downstream. This is a sophisticated pattern that was only possible because they had full visibility into what each research thread was doing at every step.
Cross-run caching reduced LLM API costs. The same research prompt hitting the same deterministic tool calls reused cached results rather than re-paying for them.
The results: within an hour of onboarding, their local BAML agent prototype was running in production. They hit 2,000+ concurrent runs, cut failure recovery time by 50%, increased development velocity by 30%, and saved significant hours per week on infrastructure maintenance.
What this means for agent builders
If you're building agents today, here's the practical summary:
Observability is necessary but not sufficient. Knowing that your agent failed is useful. Getting your agent to autonomously recover from that failure is what actually matters.
Don't aim for failure-proof. Aim for cheap failures and fast recovery. The feedback loop between failure and recovery, with full context preserved at each step, produces more reliable systems than any amount of defensive engineering.
Infrastructure is context. Infra failures should be inputs to your agent's reasoning. If you surface them correctly, an agent can see why it failed and fix it.
Secure sandboxes extend the agent's reach. When the predefined tool belt isn't enough, code-mode and stateless sandboxes give the agent a fallback path. Self-healing isn't magic, it's giving the agent the context and capabilities to fix its own inner loop.
Start simple, then scale. One agent with a good tool set works well for most use cases. One agent and one sub-agent layer covers a lot of ground. Only go deeper when the use case genuinely demands it.
The year of agents is here. The teams that build durable, observable, self-healing infrastructure underneath their agents are the ones who'll be able to ship and iterate at the pace the moment demands.
Niels Bantilan is Chief ML Engineer at Union.ai, where he leads the team building ML agents powered by Flyte. Flyte is open-source; you can find it at flyte.org.
.webp)
