Here’s What We Found
Every orchestration platform carries the assumptions of the moment it was built. Those assumptions shape what’s easy, what requires painful workarounds, and what’s simply impossible. As AI and agentic workloads expose the limits of tools designed for simpler times, the foundational data model of each orchestrator determines whether it's built for scale. Here’s a breakdown of orchestration, data models, and how leading AI orchestration tools stack up.
What Is a Data Model, and Why Does It Matter?
A “data model” is how a system represents the world: what it chooses to encode, emphasize, and enable so that users can solve a specific set of problems.
This concept applies to all layers of a product: the underlying database architecture, the developer experience, which integrations feel native versus bolted-on, even the pricing and go-to-market strategy. Building on Matt Brown’s “Your data model is your destiny,” this analysis compares the data models powering the most widely used orchestration platforms today (Airflow, Ray, Modal, Temporal, and Flyte) to help you understand which tool is right for your organization, or which abstractions to reach for if you’re building your own.
By the end, you’ll have a clear sense of what separates good, future-proof orchestration from everything else.
Three Generations of Orchestration
Before we get into how individual tools compare, it helps to understand the problem space. Orchestration as a software category has gone through three distinct eras over the past decade. Understanding what each era demanded is the key to understanding which platforms are genuinely built for the long haul and which are running on borrowed time.
Era 1: Data Orchestration
The story starts with ETL. In the early days of data infrastructure, the goal was straightforward: move structured data from one place to another, transform it along the way, and land it in a SQL warehouse. The whole job ran on a single virtual machine — one environment, one compute profile, one set of dependencies. The orchestrator’s job was equally well-defined: sequence the steps, run them on a schedule, and tell you what succeeded or failed. Tools like Airflow were built for exactly this world, and they were good at it.
Era 2: ML Orchestration
Then machine learning arrived and broke the monolithic compute assumption. Suddenly you had GPU-bound training steps sitting alongside CPU-bound preprocessing, and over-provisioning a single environment to cover both was expensive and wasteful. The right answer — disaggregate the compute, run each step on the right hardware, hand data off reliably between them — turned out to be architecturally hard. It also introduced a new class of assets (trained models and the datasets used to create them) that needed versioning, tracking, and lineage. You needed to know, months later, exactly which data produced which model. Reproducibility went from a nice-to-have to a hard requirement, and the monolithic orchestrator wasn’t built for any of it.
Era 3: AI and Agent Orchestration
Here’s where things get genuinely interesting, and where most existing orchestrators start to crack.
AI engineering, as Chip Huyen defines it in AI Engineering, is the practice of building software applications that leverage foundation models. These applications are fundamentally different from traditional software because they rely on the statistical nature of ML models to solve problems that deterministic code can’t easily handle: converting unstructured text into structured JSON, translating natural language into SQL, taking a high-level objective and breaking it into a concrete step-by-step plan.
What does this mean for orchestration? As an AI engineer, you probably start by prototyping with API calls to a SaaS LLM provider. The key thing you need from your orchestrator at this stage is flexibility. You can’t structure your application as a static DAG the way traditional orchestrators require. You need the full power of Python: conditionals, loops, try/catch error handling around LLM calls, because the LLM itself determines the shape of the program at runtime.
You also need deep visibility into execution (token usage, prompt transformations, intermediate outputs) because debugging an AI application requires understanding what happened inside a call, not just whether it succeeded or failed.
And if your prototype is successful and you decide to take it to production? Maybe that means moving from a SaaS LLM to a self-hosted small language model for cost, security, or compliance reasons. At that point, you’re immediately back in ML orchestration territory: gathering and preparing training data, fine-tuning your model of choice on GPUs, managing the lifecycle of datasets and model versions, and deploying to a serving endpoint.
Here’s the key insight: the AI era doesn’t replace the previous two eras. It stacks on top of them. An effective AI orchestrator depends on an effective ML orchestrator, which depends on an effective data orchestrator.
So is there a platform whose data model can handle all three generations without forcing you to stitch together incompatible tools?
How the Major Platforms Stack Up
Let’s take a look at what each of the major orchestrators was designed to do, and where those original design choices create structural limitations down the road.
A quick disclaimer: the descriptions below capture the distilled essence of each product’s data model, not the complete picture. Software is hackable and extensible, so functionality provided natively by one tool can often be replicated in another with enough effort. But examining the quickstart docs and example code of each platform tells you a lot about what they emphasize at their core, and what you’d be working against the grain to accomplish.
Airflow
Airflow was built for Era 1: ETL on structured data in a homogenous compute environment. Its core model centers around DAGs of operators that share a single, monolithic execution environment. This works well when your compute requirements are uniform. It becomes a real problem when different tasks need different container images, different resource profiles, or GPU access, because Airflow’s model assumes all the work runs in the same place. Extensions and plugins can paper over some of this, but you’re working against the grain of the underlying design.
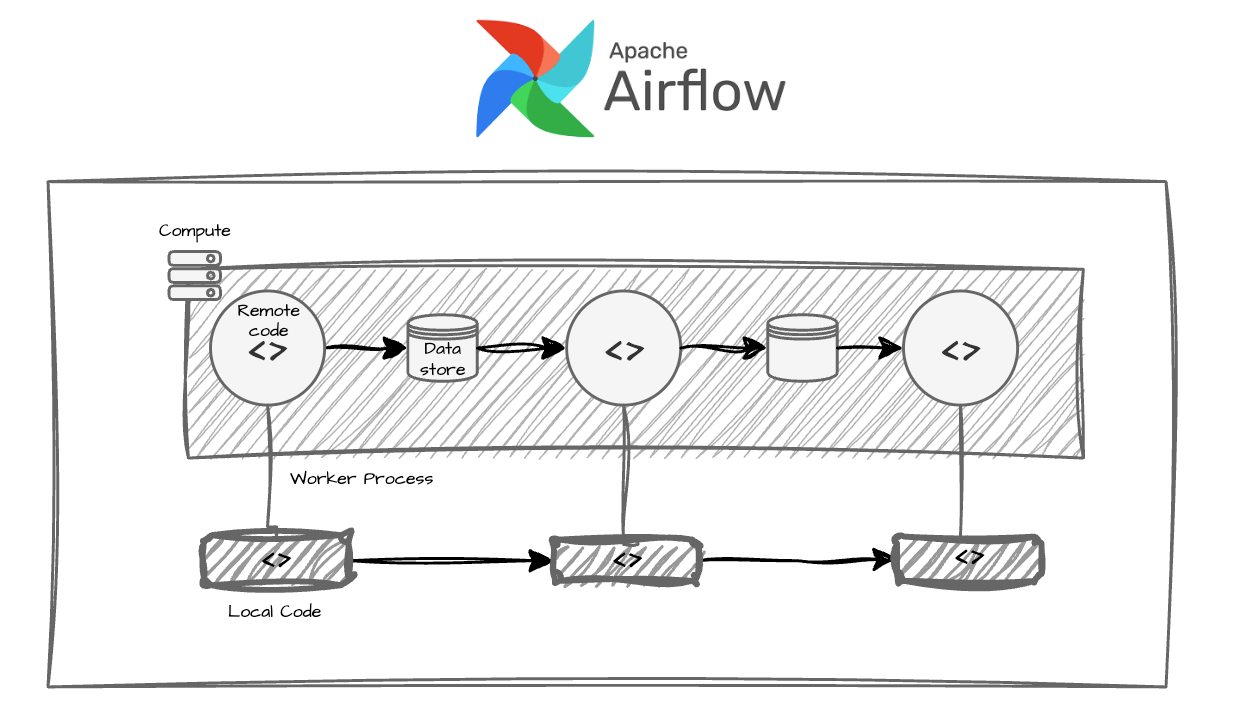
Ray
Ray was built as a distributed compute framework, and its data model reflects that: a persistent cluster with a high-performance distributed data layer. It’s excellent at sending heavy compute workloads (large-scale data processing, distributed model training) to a pool of machines efficiently. What it doesn’t give you is a native orchestration layer for discrete workflow steps. There’s no built-in concept of task-level durability, data lineage between steps, or structured retry logic across a heterogeneous pipeline. It’s a powerful engine without a gearbox.
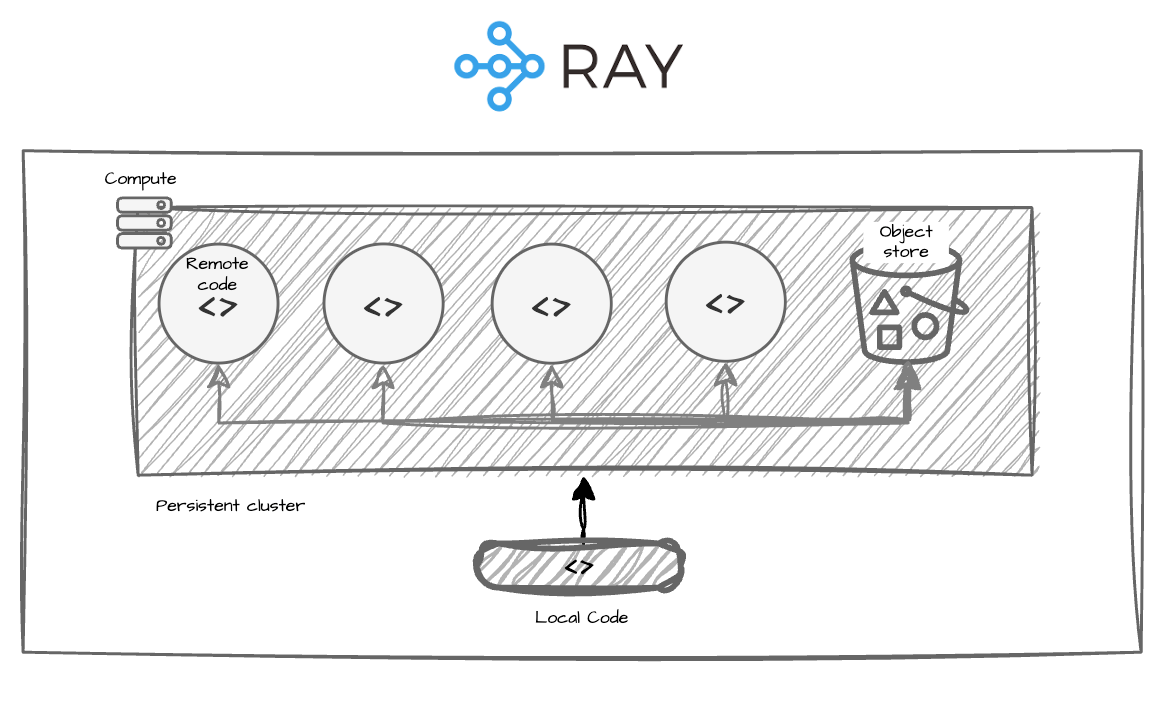
Modal
Modal is essentially serverless cloud infrastructure with first-class support for resource-aware functions. Think AWS Lambda, but purpose-built for ML workloads. You can get a GPU-backed function running in seconds. This is genuinely useful for rapid prototyping and standalone AI applications. But Modal doesn’t own your data flow. Serialization and deserialization between steps is your problem. Tracking dependencies between datasets, runs, and models is your problem. Building retry and recovery logic is your problem. Modal gives you great compute; everything else is on you.
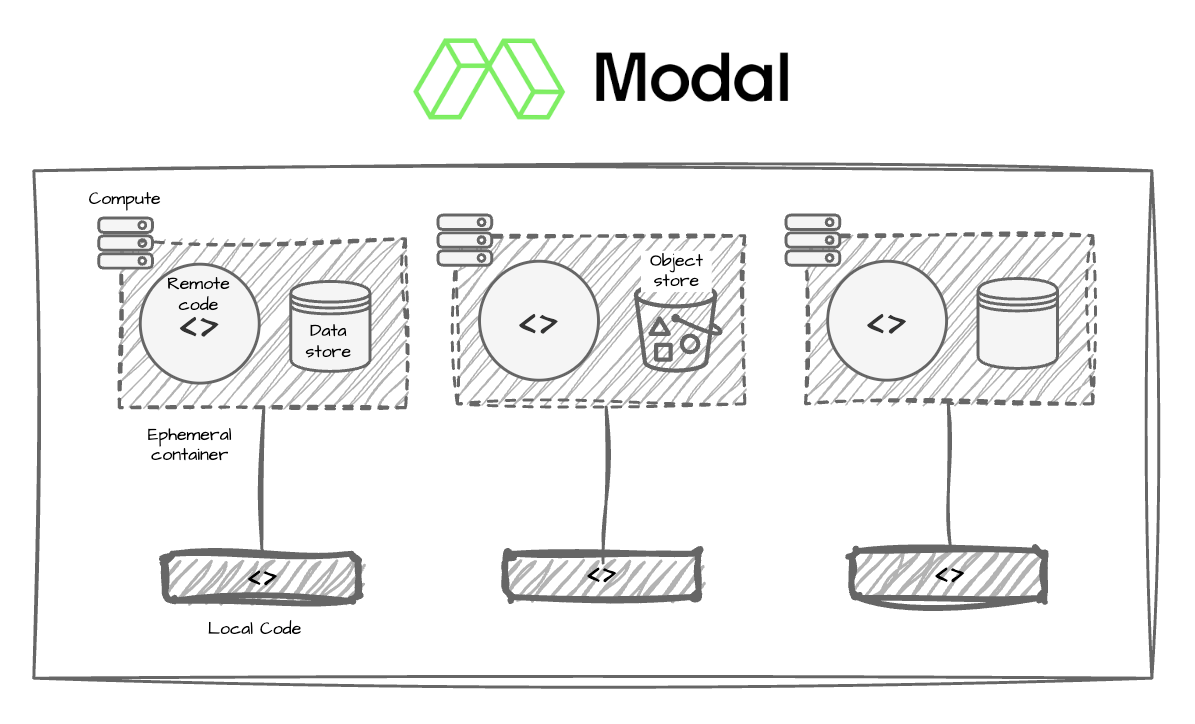
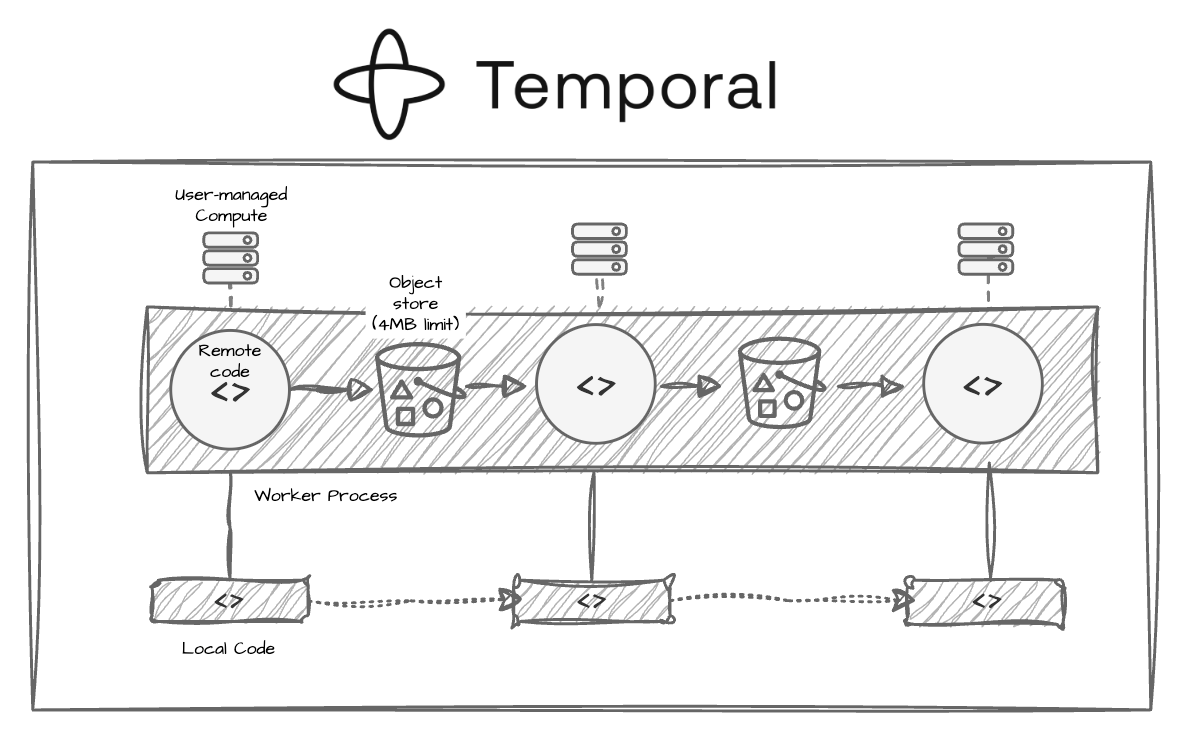
Temporal
As a durable microservice orchestrator, Temporal employs a data model that uses a replay log to achieve fault tolerance. When an execution fails, the system replays completed events to reconstruct state and picks up from where it left off, without re-running work that already succeeded. This is a powerful guarantee for distributed systems, and it’s why Temporal has found real traction in backend engineering contexts.
However, an important gap becomes visible when you move into ML and AI workloads. Temporal orchestrates activities (i.e., jobs) but has no influence over the compute those activities run on. Because it doesn’t manage compute infrastructure, it can’t solve infrastructure-caused failures, which make up ~50% of all workflow failures. These failures (e.g., out-of-memory errors and container preemption) become more common as workloads become more resource-intensive. When a GPU process gets OOM-killed or a spot instance gets preempted, Temporal surfaces an activity failure. What to do about it is entirely outside its model. Teams end up maintaining a parallel system for compute orchestration and data tracking alongside Temporal, which defeats much of the value of having a unified orchestrator in the first place.
Flyte: The Right Data Model Changes Everything
Look at everything the platforms above are missing and a pattern emerges. Airflow can’t disaggregate compute. Ray has no data lineage layer. Modal leaves the plumbing of intermediate state to you. Temporal can’t see the compute infrastructure. Each gap traces back to the same root cause: none of these platforms were built with heterogeneous, data-intensive ML workloads as their primary problem to solve.
Flyte was. And the answer it arrived at is surprisingly simple. Flyte’s entire model rests on two ideas:
- Run containerized code through resource-aware functions (i.e., tasks or actions) that can be composed into workflows.
- Let the platform handle data movement, persistence, and tracking between tasks via Python’s native type system.
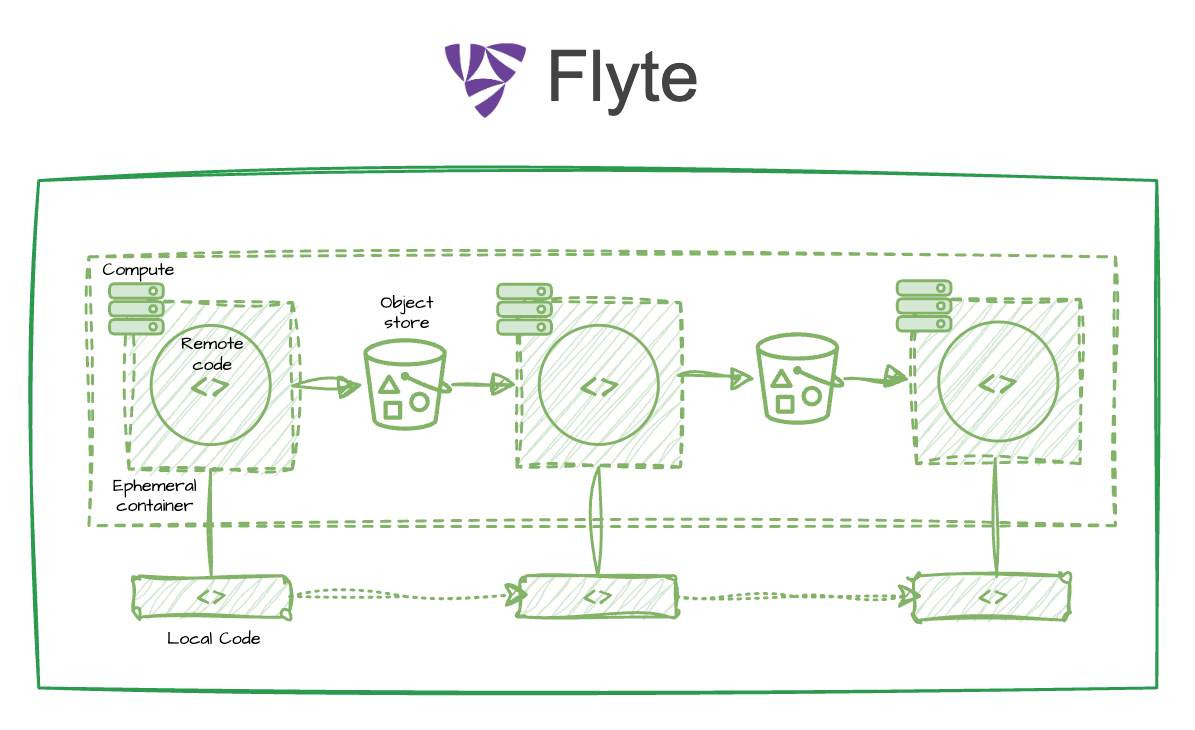
That’s it. Everything else — the scalability, the fault tolerance, the lineage, the cost visibility — is a consequence of taking these two ideas seriously.
Let’s unpack what this data model means.
Containerized Code
The “but it works on my laptop” problem is endemic to ML (and AI) development. Flyte’s unit of compute is a containerized function: your business logic runs in a common environment consistent for your whole team, with the dependencies you’ve specified. Results are reproducible, and you eliminate an entire category of debugging. You’re never trying to reconcile why the same code behaves differently across environments.
Composable, Infrastructure-Aware Tasks
Each task can declare its own compute requirements independently. A data preprocessing task runs on a CPU node. A model training task requests a specific GPU type and memory allocation. An evaluation task scales across dozens of CPU workers in parallel. Flyte provisions the right compute for each task and tears it down when it completes. The efficiency this creates is now an architectural prerequisite for building real ML systems rather than toy pipelines.
Handling Data Movement, Persistence, and Tracking Between Tasks
Flyte allows you to write tasks like regular Python functions with input and output type hints. This eliminates the glue code (the code that shuffles data between steps and tools) you would normally need to implement to read/write your datasets and models to object storage. In a complex ML pipeline, that glue code is also a primary source of bugs, version mismatches, and failures.
Data SerDes via Python’s Type System
Flyte uses Python type hints as a metadata layer for automatic data serialization and deserialization. When a task returns an output, Flyte knows how to write it to an object store. Then, it can read the output from the object store when you need it for another downstream task. The type system becomes the contract between tasks, and Flyte handles all the plumbing.
Flyte’s Data Model Unlocks
Put these properties together, and the following are simply the default behavior, not things you have to engineer yourself:
- Disaggregated compute: each task gets exactly the resources it needs, and no more.
- Automatic (and fast!) SerDes of data: no manual serialization, no hand-rolled storage logic, no schema drift between steps.
- Inherent scalability: because tasks run in isolated containers, Flyte can fan out any workload to arbitrary parallelism at the scale of Kubernetes.
- Fault tolerance: Flyte knows exactly what has succeeded and failed at task granularity, so retries and recovery are fast and cheap.
- Lineage by default: every artifact in the system is tracked, versioned, and connected to the tasks that produced and consumed it.
The Compounding Data Model
Here’s the thing about a well-designed data model: it doesn’t just solve today’s problems. It makes tomorrow’s solutions obvious as you scale, add complexity, and demand more from your AI systems. A compounding data model is one in which adding a new feature achieves a “network effect” between it and many of the prior features before it. The result is a platform that grows more integrated and valuable as it matures, rather than accumulating independent features that users have to manually stitch together.
Flyte uses a compounding data model, thanks to these three dimensions:
Enhancing Tasks as the Core Compute Unit
Tasks are enriched by providing users with different ways of running them (on a schedule, via webhooks, on certain events firing), by exposing interactive entrypoints to debug code inside the container directly, and by leveraging open source technologies that are purpose built for specific parts of the AI/ML lifecycle.
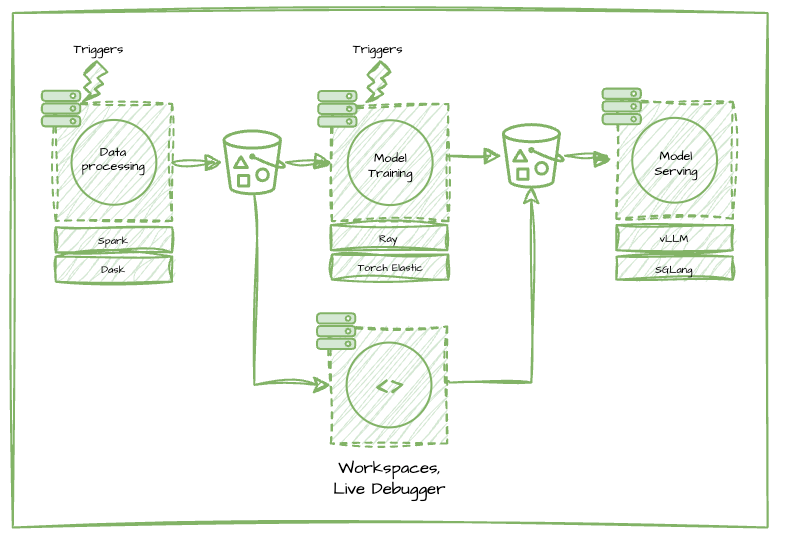
Caption: Debug tasks live in dev or prod directly on the K8s pod, create workspaces to develop code as close to production compute as possible. Use cron triggers to automate tasks on a schedule, and leverage integrations like the pytorch Elastic (i.e. torch run), Spark, Ray, and Dask plugins to unlock distributed workloads from data processing to model training.
Elevating Data as a First-Class Asset
With data as the core assets produced by these tasks, which includes both training datasets and models, platform capabilities are supercharged by improving data reads and writes, providing an artifact registry to version, persist, and discover data as a first class citizen, and unlocking reactive patterns of executing tasks based on artifact materialization events.
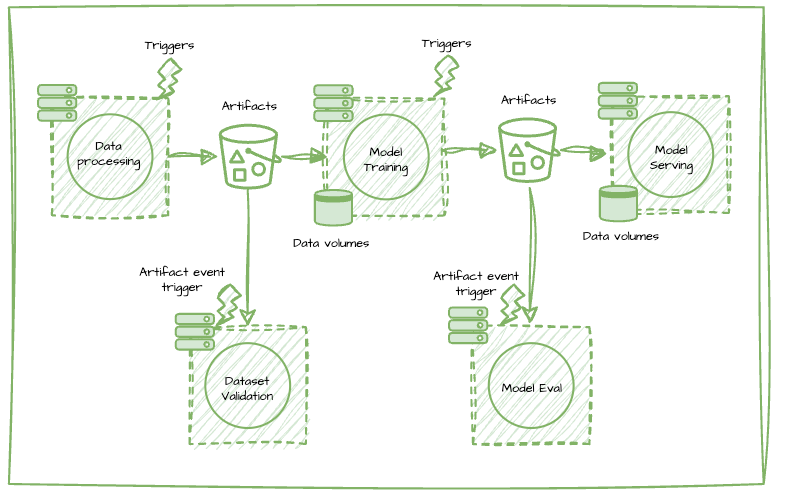
Caption: Accelerate system-wide reads and writes from object storage with the Flyte Rust core and speed up dataset reads across all tasks with mounted data volumes. Persist, version, and easily manage datasets/models produced by tasks with Artifacts. Kick off workflows when a new model is trained or a fresh dataset is created with Artifact Triggers. Validate large scale data in your object store or data warehouse with the Flyte pandera plugin and Reports, and evaluate models offline to understand how model performance is changing over time.
System-Wide Observability and Optimization
Finally, because of all the network effects between the features and entities on the platform, Flyte can provide system-wide observability and optimization capabilities that help enterprises manage their cost and leverage compute resources in neo-clouds like Nebius for GPU-heavy workloads.
Caption: Optimize the overall and granular cost of your projects since Flyte captures all metadata about tasks, their compute requirements, and the datasets/models they produce. Understand the big picture of how your model was built, from dataset to model endpoint with Artifact Lineage tracking. Avoid overprovisioning compute resources for your tasks with a global resource utilization dashboard.
Ultimately, the benefit of a compounding data model is that decisions about what to build next should become obvious, and whatever you do build next will have an outsized return because of all the context that feature obtains based on all the existing features.
Flyte 2: Self-Healing, Dynamic Workflows
Flyte 2 takes this data model and runs. In a world increasingly populated by agents, dynamism at runtime and durable execution have stopped being optional.
One thing we kept hearing from Flyte 1 users was: “We love the durability and resiliency of Flyte workflows, but we want more flexibility.”
By “more flexibility”, they meant a laundry list of dynamic orchestration capabilities:
- Parallelizing tasks and workflows over tens of thousands of elements.
- Custom behavior for handling errors in massively parallelized workloads.
- Autonomously catching exceptions (e.g. out-of-memory errors) and handling them with custom business logic.
- Dynamically overriding resource requests as a response to task inputs or inline errors.
- Using for/while loops and conditional logic to dynamically change a workflow’s execution path.
- Leveraging Python’s async programming to fully control concurrency.
Based on this overwhelming feedback, we decided to make one major change to the underlying platform while preserving Flyte’s core data model: get rid of static DAGs (directed acyclic graphs), which are the mainstay of many orchestrators, and enable fully dynamic and durable orchestration.
In other words, there is no special entity in the system called a Workflow. When I want to compose tasks together, I just create a task that calls tasks.
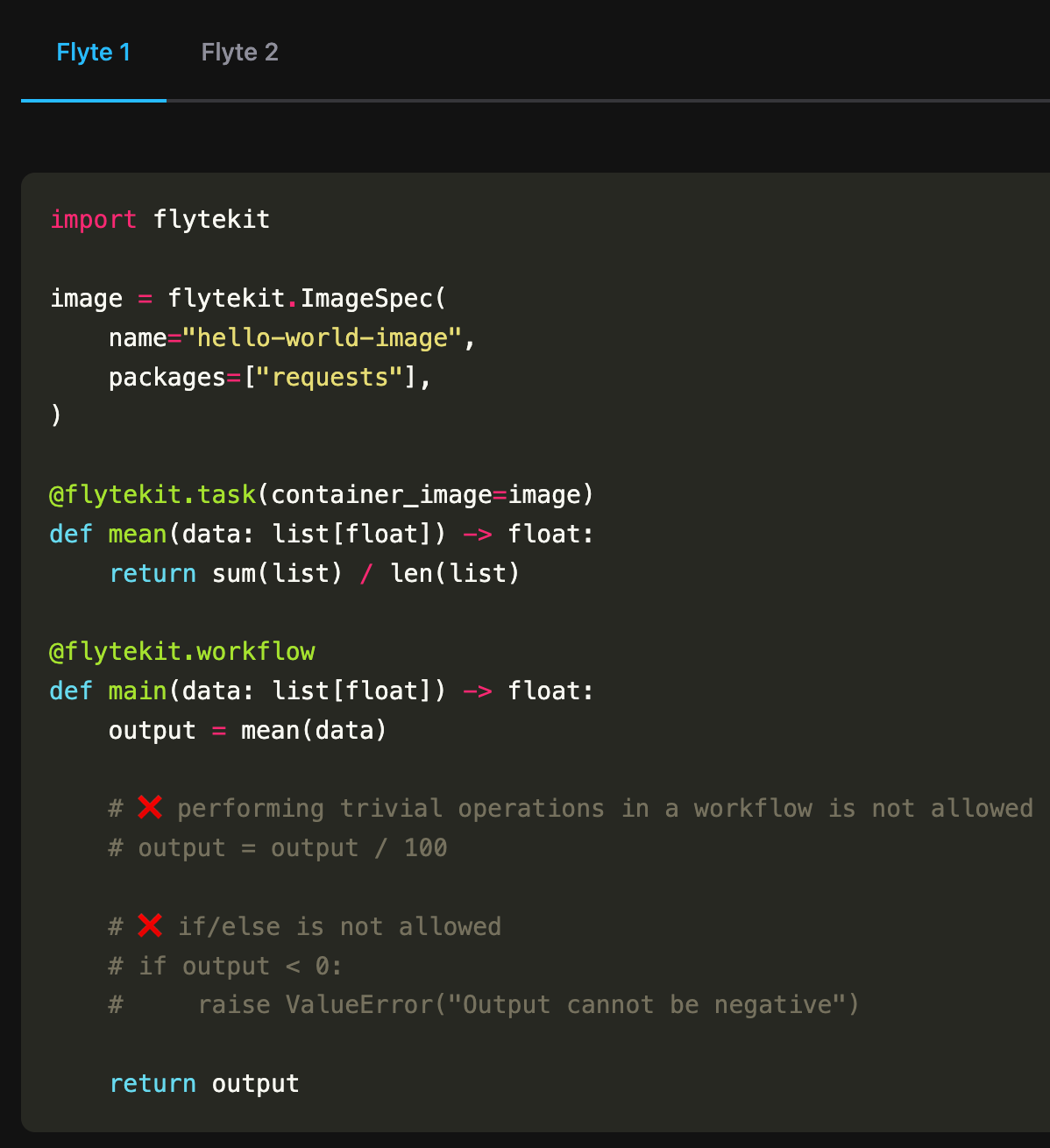
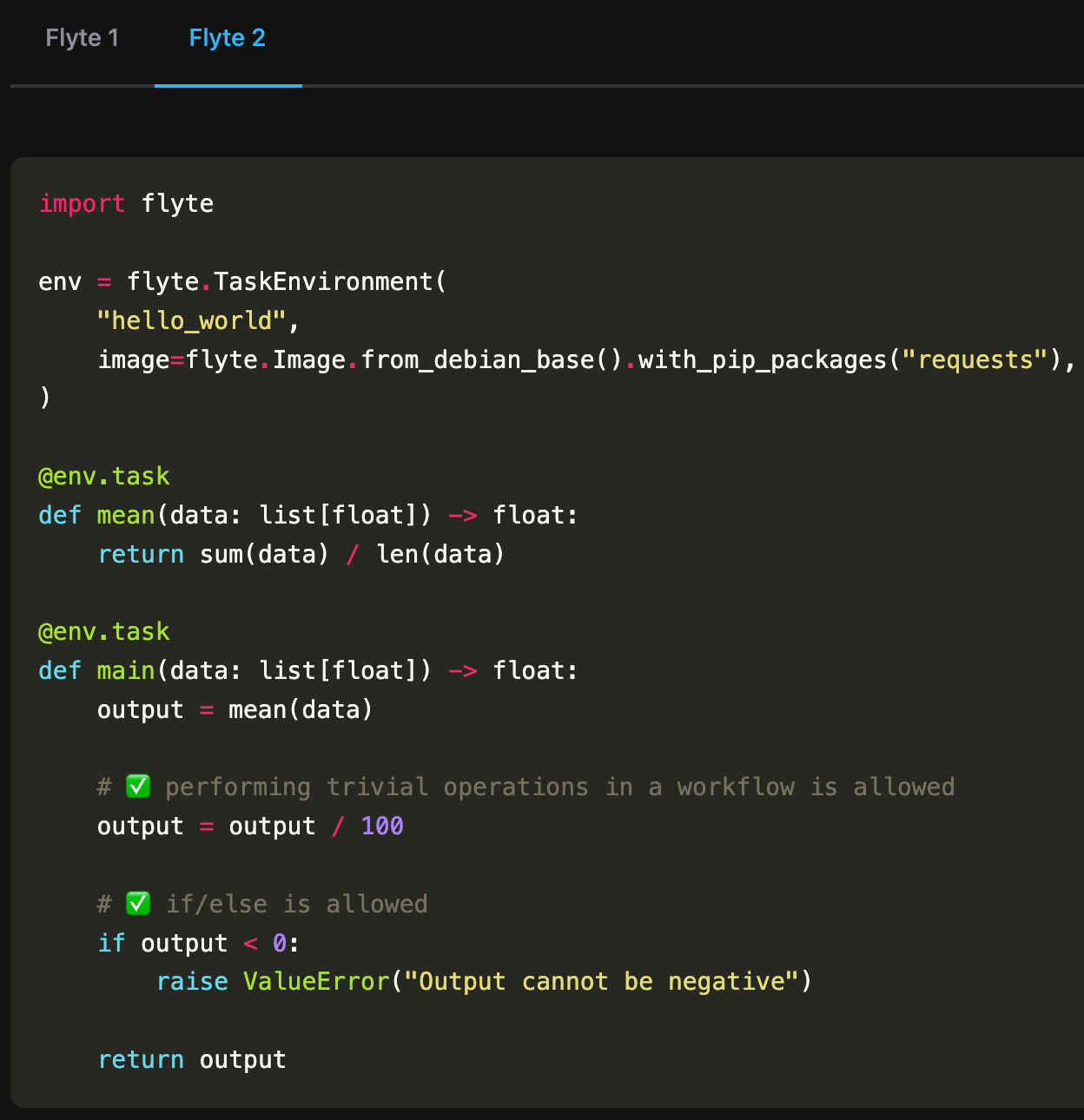
Compare Flyte 1 vs. Flyte 2
With full dynamism, we also had to innovate to achieve durability. Instead of relying on a static DAG to guarantee durable workflows, Flyte 2 uses a “replay log” that deterministically tracks what has already happened in a particular run. This means that when I get an error (e.g., an intermittent network failure), the system can recover the run from where it left off without having to re-run the tasks it had already completed. Crucially, this even applies to infrastructure-caused failures.
And because Flyte 2 autonomously handles both logic and infrastructure failures, Flyte workflows are self-healing.
At its core, Flyte 2 still centers around containerized, resource-aware functions (i.e., tasks), provisioning disaggregated compute resources for the underlying workloads, and handling data movement and persistence between tasks.
Choosing the Right Tool
The right AI orchestrator for you is the one whose core abstractions align with the problems you’ll actually face as your system grows. If your workloads are purely data engineering, Airflow may be all you need. If you want serverless compute flexibility and are willing to build your own data and lineage layers, Ray will serve you. Modal can do the same with its serverless compute, as long as you’re comfortable with your data leaving your own infrastructure. If you’re orchestrating backend microservices, Temporal is genuinely good at that.
But if you’re building AI systems (if you need to move from raw data to trained models to deployed applications and back again), the architectural cost of assembling these capabilities from tools that weren’t designed for it adds up quickly. You’ll spend engineering time on glue code, on reconstructing lineage, on building retry logic, on reconciling compute environments.
Flyte was built on the assumption that the full AI development lifecycle is one problem, not three separate problems stitched together. As AI systems grow more complex and agentic workflows become the norm, designing your AI stack to scale with you is critical.
Conclusion
The initial conditions of any software system constrain its possible futures. The choices made at a platform’s conception (about which problems matter, which abstractions to reach for, what to own versus leave to the user) shape not just what the platform can do today, but how much it can scale with you without buckling under its own weight.
The data model you choose today will determine what you can build tomorrow.
Learn more about Flyte at flyte.org
Or chat with a Union.ai engineer about managed Flyte: